信号流
2026-06-17·17 条·5 值得深看
2026-06-17
2026-06-17
最新17 条信号superpowers 231k 星:agent skills 从一个功能长成独立方法论↗
1.1k stars/d→ 结论先行:skills 已经从『Claude 的一个功能』变成独立的开源生态和方法论,这是个该跟的趋势信号。对你的价值不在直接用 superpowers,而在认清『把反复踩的坑 / 工作流固化成 skill』正在成为 agent 工程的标准做法——HN 那条 Claude hacks 也在说同一件事。把自己日常的抓取 / 打分 / 排版流程沉淀成可复用 skill,长期比每次重新提示省力,也是 daily-web 想做『自我进化』该走的路。
值得深看
superpowers 231k 星:agent skills 从一个功能长成独立方法论↗
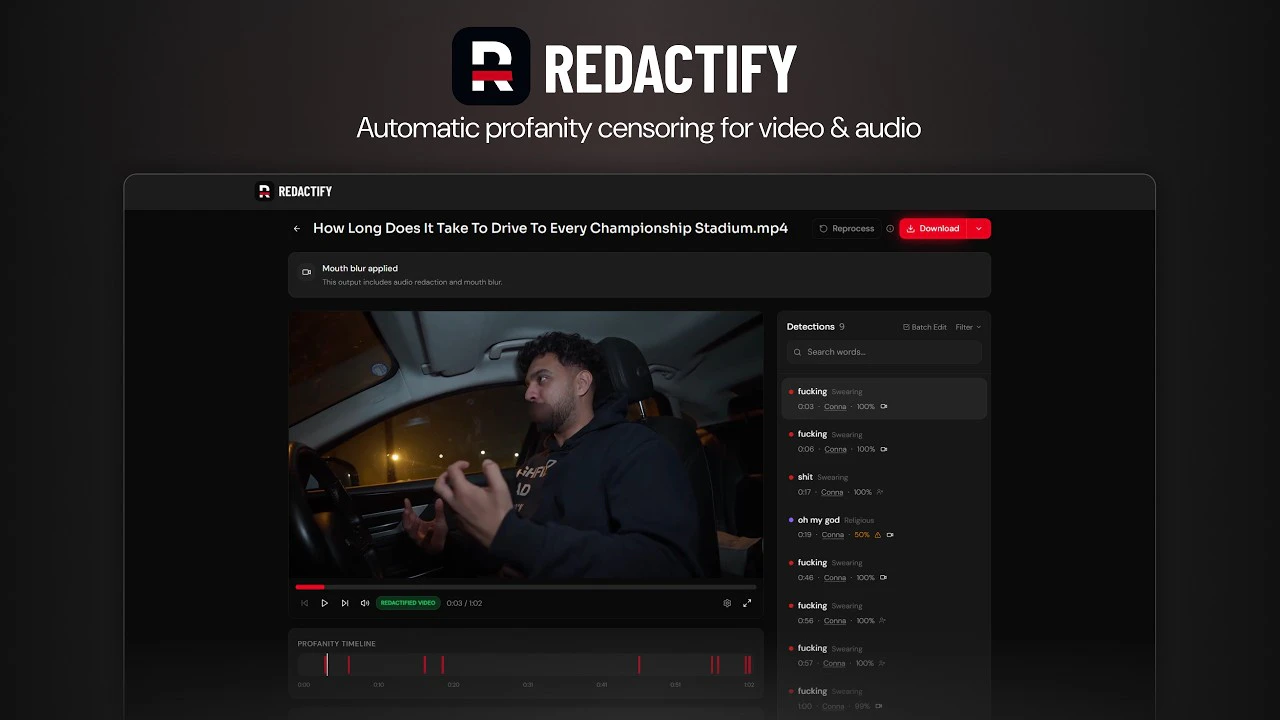
1.1k stars/d→ 结论先行:能做、嗅着蓝海的垂直音视频工具。痛点真实且具体——平台对脏话有审核 / 去货币化风险,创作者现在多半手动消音。门槛在能力内(语音转写定位脏词 + 自动 bleep + 嘴部模糊),而「模糊嘴防唇读」这种细节恰恰是纯 wrapper 做不出的差异点。蓝海方向是垂直到合规场景(平台安全词、儿童内容、品牌安全)。真实关键词从站点 title/desc 提炼,竞争看着不高,值得 Semrush 验一把。
值得深看

HummingBytes — 一张粗照片出全渠道电商产品图↗
→ 结论先行:正中你图像主业,能做、嗅着蓝海。痛点真实(中小卖家拍不出专业产品图、各渠道尺寸规格还不同),解法是『一张照片 → 全渠道规格化素材』。差异化不在文生图模型,在『按销售渠道出规格素材』这层电商垂直——纯 ChatGPT 给不了 Amazon / TikTok Shop 的成品规格。蓝海词从站点 title/H1 提炼、意图明确、竞争中等,跟 tryonfy 虚拟试穿是产品线邻接(都是电商图像)。
值得深看
HummingBytes — 一张粗照片出全渠道电商产品图↗

ManualFig — 产品照片转说明书线稿插图(窄蓝海,关键词意图极垂直)↗
→ 结论先行:窄而真的蓝海,能做,门槛在『输出能跟着做的线稿图而非炫酷渲染』。痛点具体——做说明书 / 装配图要么请技术插画师贵、要么自己画慢,目标客户明确(硬件 / 家具 / 小家电卖家)。它列的真实关键词(product line art generator / instruction manual generator with pictures)意图极垂直、商业价值高、竞争看着低,是 TAAFT 今天最值得 Semrush 验的一条。差异点是『线稿 + 编号步骤』这种 manual-ready 输出,纯通用文生图做不出。
值得深看
ManualFig — 产品照片转说明书线稿插图(窄蓝海,关键词意图极垂直)↗

→ 结论先行:小而实的创作者工具,能做、门槛低。痛点具体(横竖屏二次制作),解法在拍摄端一次出两版而不是事后裁。机会不在再做一个剪辑器,而在这个『capture-time 解决』的角度。但天花板低(单一功能、Android app),更像引流钩子而非主产品。真实关键词来自 Google Play 描述。
值得知道

OpenMontage:开源 agentic 视频生产系统,把 AI coding 助手变视频工作室↗
98 stars/d→ 结论先行:这是『AI 视频生产』开源化的信号,对做内容 / 工具站的人有两层意义。机会上——自动化视频生产(脚本 → 分镜 → 配音 → 剪辑)正被开源工具拉低门槛,内容站可以借它批量产出 YouTube / 短视频引流素材;警惕上——它把视频生产做成 agent skills 集合,意味着这块也在快速商品化,纯『帮你做视频』的 wrapper 窗口在收窄。先当可复用资产记着,真要用再看它流水线怎么拆。
值得知道
OpenMontage:开源 agentic 视频生产系统,把 AI coding 助手变视频工作室↗
98 stars/d→ 结论先行:契合内容 / SEO,能做但已有同类。它解决「YouTube 评论是选题金矿但没人手翻得完」的真痛点,且『每条洞察可溯源到真实评论』是反 AI 幻觉的卖点——这正是 daily-web 自己抓评论挖需求的同一套逻辑。对做内容站的人,思路可借:把评论区挖成选题 / 需求来源。蓝海有限(YouTube 评论下载工具不少),缝隙在『带引用的分析报告』而非裸导出。真实关键词来自站点 H1/H2。
值得知道

→ 结论先行:产品本身是 demo、不成熟,但『菜品 / 商品名 → 可视化图』这个 image-generation 垂直场景值得嗅,跟你图像主业沾边。机会在把『文字描述 → 真实感图像』垂直到有明确场景的地方(菜单、装修、商品详情),而不是泛泛文生图。当前更多是方向提示而非可抄的成品,seo_keywords 因真站没实际内容只给方向假设、待验。
值得知道
headroom:喂给 LLM 之前先压缩,省 60-95% token——省钱长成了一个工具品类↗
22 stars/d→ 结论先行:直接呼应今天的 token 成本主线,是个能复用的省钱资产。如果你的 agent 流程里有大量 tool output / 日志 / RAG 喂进 context(daily-web 读全量 snapshot 打分正是这种),这类『喂给模型前先压缩』的中间层能实打实砍账单,值得评估接进抓取 → 打分链路。把它和 Reddit 那条 token 求助、HN 那批用量监控放一起看:省 token 已经从『调参技巧』长成一个有库、有 proxy 的工具品类。
值得知道
headroom:喂给 LLM 之前先压缩,省 60-95% token——省钱长成了一个工具品类↗
22 stars/d→ 结论先行:这是竞品监控,归你出海增长方向的直接对标,不是新机会。它把『自动回复涨粉』做成 agent,卖点押在『像你 + 不被封』。真正值得记的是它落地页那句 H2——『每个回复工具都死了,Fireply 没有』:这种自我防御式文案恰恰暴露品类极度拥挤。对你更像『别进这个红海』的反向情报,而不是可切的机会。真实关键词为站点 meta keywords。
值得知道
ppt-master:任意文档转『真·可编辑』PPT,差异点正是用户会买单的地方↗
14 stars/d→ 结论先行:『文档 → 可编辑 PPT』是个有明确付费场景的方向,门槛在『输出真原生 PPT 而非图片』这个技术点。多数 AI PPT 工具吐出来的是不能改的图,ppt-master 的差异恰恰是可编辑的原生形状——这正是用户真正会买单的地方。对做工具站的人,这是值得嗅的细分:垂直到某类文档(论文 → 答辩 PPT、财报 → 路演 PPT)再叠加套用户模板,可能有缝隙。蓝海词假设 document to powerpoint / editable ai ppt,量级待 Semrush 验、竞争中等。
值得知道
ppt-master:任意文档转『真·可编辑』PPT,差异点正是用户会买单的地方↗
14 stars/d→ 结论先行:这是 daily-web 的远亲(新闻聚合 + AI 摘要),但走『个人订阅 + 多语种音频』路线,跟你的『阅读视角情报站』不同。值得记两点:① 它再次印证 HN 那条『想要每周自动总结的 agent』——AI 新闻摘要订阅是真市场(今天 GitHub、HN、PH 三处撞上);② 它的差异化是『你的语言 + 音频简报』,对出海做内容的人,『把英文信息源转成本地语言音频』是个可借的角度。真实关键词为站点 meta keywords。
值得知道

ProofWrite — 主打『先调研后写、带引用事实核查』的 SEO 文章工具↗
→ 结论先行:SEO 主业相关,既是竞品也是方法借鉴。它定位很聪明——不喊『AI 写得快』,而是『research first, write second + 带引用事实核查』,精准踩中 AI slop 内容被 Google 和编辑嫌弃的痛点(呼应今天 brevio 那条对凑词 SEO 页的反感)。对你做内容 / 外链的启示:现在能立住的不是量产 AI 文,是『有调研 + 可溯源』的内容,客座文尤其如此。它『围绕客户链接做独立文章』的玩法跟你外链 pitch 思路相通,值得借。
值得知道
ProofWrite — 主打『先调研后写、带引用事实核查』的 SEO 文章工具↗

ATS Helper — 把竞品收费的点全做免费的简历工具↗
→ 结论先行:免费工具吃高意图词的现成样本,能做、门槛低。简历是常青刚需,『ATS 友好 + 免费 + 无付费墙 + 隐私』四个卖点全冲着付费简历工具的痛点去(多数简历站卡在导出收费)。打法可抄:拿一个高频刚需 + 把竞品收费的点全免费 + 隐私本地化建信任,靠 free resume builder / ATS resume 这类大词的自然流量起量,再想变现。这跟今天 brevio『免费工具站』、Reddit 的 DR checker『免费查询引流』是同一套路,反复出现说明它有效。
值得知道
ATS Helper — 把竞品收费的点全做免费的简历工具↗

World Cup Fan Card — 蹭 2026 世界杯的个性化周边生成器↗
→ 结论先行:蹭 2026 世界杯热点的图像小工具,可做、窗口短。它的价值是个时效性 programmatic SEO 样本——抓一个大型赛事热点 + 个性化图像生成(照片转主题卡)+ 周边变现。套路可复用到任何有粉丝文化的大事件(球赛、演唱会、电竞赛事),关键是赶在热度窗口内铺词。注意它定价 $9.90/周很激进,说明这类热点工具是『短期收割』而非长期站。蓝海词随赛事 + 时间限定波动。
值得知道
World Cup Fan Card — 蹭 2026 世界杯的个性化周边生成器↗

Drafted — 100% 免费 AI 户型图 + 8.5 万程序化页,deroomai 直接竞品↗
→ 结论先行:这是 deroomai(AI 家居设计)方向的直接竞品监控,重点看它的打法。它走『100% 免费 + 海量程序化页(85,000+ 户型)+ 免费 CAD/PDF 下载』路线,用免费 + 规模吃 AI house plan / free house plan 这类高意图词的自然流量。对 deroomai 两点启示:① 免费下载(CAD/PDF)是这个品类拉流量的强钩子;② 程序化生成海量户型页占长尾确实可行。要警惕它把价格压到 0 在抢同一批词——deroomai 的差异化得往设计质量 / 风格 / GMV 转化走,别在『免费户型』上硬拼价格。
值得知道
Drafted — 100% 免费 AI 户型图 + 8.5 万程序化页,deroomai 直接竞品↗

2026-06-16
20 条信号Agent skill 生态爆发:trending 被 Claude/Codex skill 刷屏↗
22 stars/d→ 结论先行——这波对你是『分发渠道』信号,不是让你再写一个 skill。你已经在用 taste-skill / impeccable / humanizer / RTK,说明 skill 已是真实工作流的一部分。能落地两点:① 把自己反复用的私有工作流(daily-web 打分 SOP、SEO 选词流程)固化成 skill,本身可能就是个有星有流量的开源资产 + 获客入口;② 盯哪类 skill 在涨(设计、写作去味、PPT、研究综合),那就是『AI 用户现在最缺的能力』的实时榜单。
值得深看
Agent skill 生态爆发:trending 被 Claude/Codex skill 刷屏↗
22 stars/dlast30days-skill:把『跨 Reddit/X/YouTube/HN 研究综合』做成了一个 skill↗
19 stars/d→ 结论先行——这是 daily-web 最直接的同构对手,但形态不同:它是给个人 agent 用的『问一次答一次』skill,你是有阅读视角 + 打分 + 线索沉淀的站。值得做两件事:① 扒它的多源研究 + 综合 prompt,看有没有能反哺你 scan / 打分的;② 想清差异化——护城河在『每天有人替你筛 + 个人画像漂移』的持续性,别被一个通用 skill 比下去。
值得深看
last30days-skill:把『跨 Reddit/X/YouTube/HN 研究综合』做成了一个 skill↗
19 stars/d→ 这几乎是你内容站 / SEO 矩阵的现成模板,能做、门槛极低(每个计算器就是个公式 + 落地页)。蓝海点在垂直选品复制:宠物之外,家居(油漆用量 / 瓷砖 / 房贷)、游戏(伤害 / 概率计算器)都同构,跟你 Pokopia 那条内容线最贴。这类站不靠订阅,靠流量 + 联盟 / 广告变现。
值得深看
RealSmile — looksmaxxing 测脸(病毒级 SEO 蓝海)↗
→ 结论先行——这是个被验证过的病毒级 SEO 蓝海,沾你图像方向、能做、变现路径清晰(免费测 + 付费报告)。looksmaxxing / face score / golden ratio 这类词搜索量大、意图明确、社交传播性极强(『和朋友比脸』自带裂变)。要做想清两点:① 内容尺度(别滑向容貌焦虑营销的雷);② 差异化在垂直场景(约会照 / 证件照 / 特定人群),别做又一个通用打分器。
值得深看
RealSmile — looksmaxxing 测脸(病毒级 SEO 蓝海)↗

Aura Cast — AI 八字算命出海↗
→ 结论先行——玄学 / 算命是出海内容站的经典蓝海(情感刚需 + 高复访 + 低履约成本),能做。BaZi / chinese astrology / feng shui 这些词在英文市场认知在涨、竞争还没饱和。可落地:用 programmatic SEO 铺『生肖 / 星座 / 黄道吉日』长尾页导流,再用每日运势做留存、年度报告做付费转化。$10/mo 订阅说明这群用户愿付费。
值得深看
Aura Cast — AI 八字算命出海↗

VoxCPM2:当天增速王,tokenizer-free 多语种 TTS↗
408 stars/d→ 对做内容 / 视频 / 工具站的人,这是『优质 TTS 开始开源化』的信号——配音、有声内容、视频旁白的成本在往下走。能用在哪:给攻略 / 教程内容站加语音版、给短视频批量配音。先放 watchlist,真要用得看它中文音色质量和商用授权。
值得知道
VoxCPM2:当天增速王,tokenizer-free 多语种 TTS↗
408 stars/d→ 沾你图像生成方向、能做,但广告创意是大厂 + 一堆工具的红海,正面拼没优势。真正值得抄的不是产品是定价与话术——『pay for output not for seats(按产出付费,不按座位)』+『初级设计师 $4000/月才出 4 条广告,我是它的零头』这种对比,是 AI 工具卖点的好范本,可直接套到你自己的产品文案上。
值得知道

→ 能做但本质是托管 / 发布层,要跟一堆 page builder 抢,不建议正面进。值得盯的是这个定位本身:AI 生成内容爆炸后,『一键发布 + 给个链接』这层的需求在涨,是个可观察的缝——先放进 watchlist,看它跟同类(v0、bolt 的 publish)怎么分化再判断要不要碰。
值得知道
Agent-Reach:给 AI agent 一双看整个互联网的眼睛↗
49 stars/d→ 跟 last30days-skill 一个方向(让 agent 能跨平台抓内容),也跟 daily-web 的抓取层重叠。值得扒它怎么解决各平台的抓取 / 登录态问题(尤其 X、Bilibili),可能有能复用到你 scan 脚本的工程经验。当工程参考,不是产品机会。
值得知道
Agent-Reach:给 AI agent 一双看整个互联网的眼睛↗
49 stars/dheadroom:内容进 LLM 前先压缩,省 60-95% token↗
19 stars/d→ 跟今天 HN/Reddit/PH 的 AI 成本主线是同一根弦。对自己跑大量 agent 任务的人有直接价值(省钱)。机会角度:token 压缩这层已经有 RTK、headroom 在卷,别再做通用压缩器;但『针对某类高频场景(RAG / 日志)的专用压缩』可能还有缝。
值得知道
headroom:内容进 LLM 前先压缩,省 60-95% token↗
19 stars/d→ 对你是双重信号:一是它是 daily-web 的近亲(社交信号监听),可以扒它怎么把『监听』做成付费产品;二是『social listening 找客户』本身是个付费意愿明确的方向。能做,但要避开『教人发垃圾广告』的雷——做成『需求情报』比『自动回帖』干净,也更对你的阅读视角。
值得知道
→ 时机新、竞争还浅,沾你图像方向、能做。但碰之前想清定位:去可见水印是正常工具,去隐形溯源标记(SynthID / C2PA)是灰色地带,别往「帮人洗 AI 痕迹规避检测」上靠——做「清理自己图片的元数据 / 残留水印」更稳,也更经得起平台审查。
值得知道
infinite-canvas:面向 AI 创作的开源无限画布(生图/改图/生视频)↗
6 stars/d→ 沾你图像生成主业。它本身是工具不是机会,但暴露了一个方向——『把分散的生图 / 改图 / 生视频串成一个画布工作流』是涨的需求。对 Deroomai 这类,可借鉴它的画布式编排交互;要不要做成独立产品另说,先当交互参考收着。
值得知道
infinite-canvas:面向 AI 创作的开源无限画布(生图/改图/生视频)↗
6 stars/d→ 能做但已经挤了。这条更多是『需求被反复独立验证』的又一佐证(今天 HN/Reddit/PH 三源都冒)。真要切,往它没覆盖的做差异化——跨 Claude / Codex / Cursor 的统一用量视图、团队预算与告警,别再做一个只盯单 Claude 的用量条。
值得知道

→ 能做、对口,但要泼冷水:image converter / background remover 是红到发紫的大词,新站硬刚首屏没戏。机会只在更窄的格式对(avif / heic 这类冷门转换)或叠加 AI 增量(批量、API),别正面拼大词。当竞品参考意义大于直接抄。
值得知道
→ 能做,但它是 app(端上推理)门槛比纯网页高。真正值得借鉴的是护城河打法:六个小工具捏成一个 app + 隐私当卖点(『我们永远看不到你的脸』)。如果你做轻量版,走网页 + 服务端反而更快上线——把『拍照诊断 + 结构化报告』这套搬到别的垂直即可。
值得知道
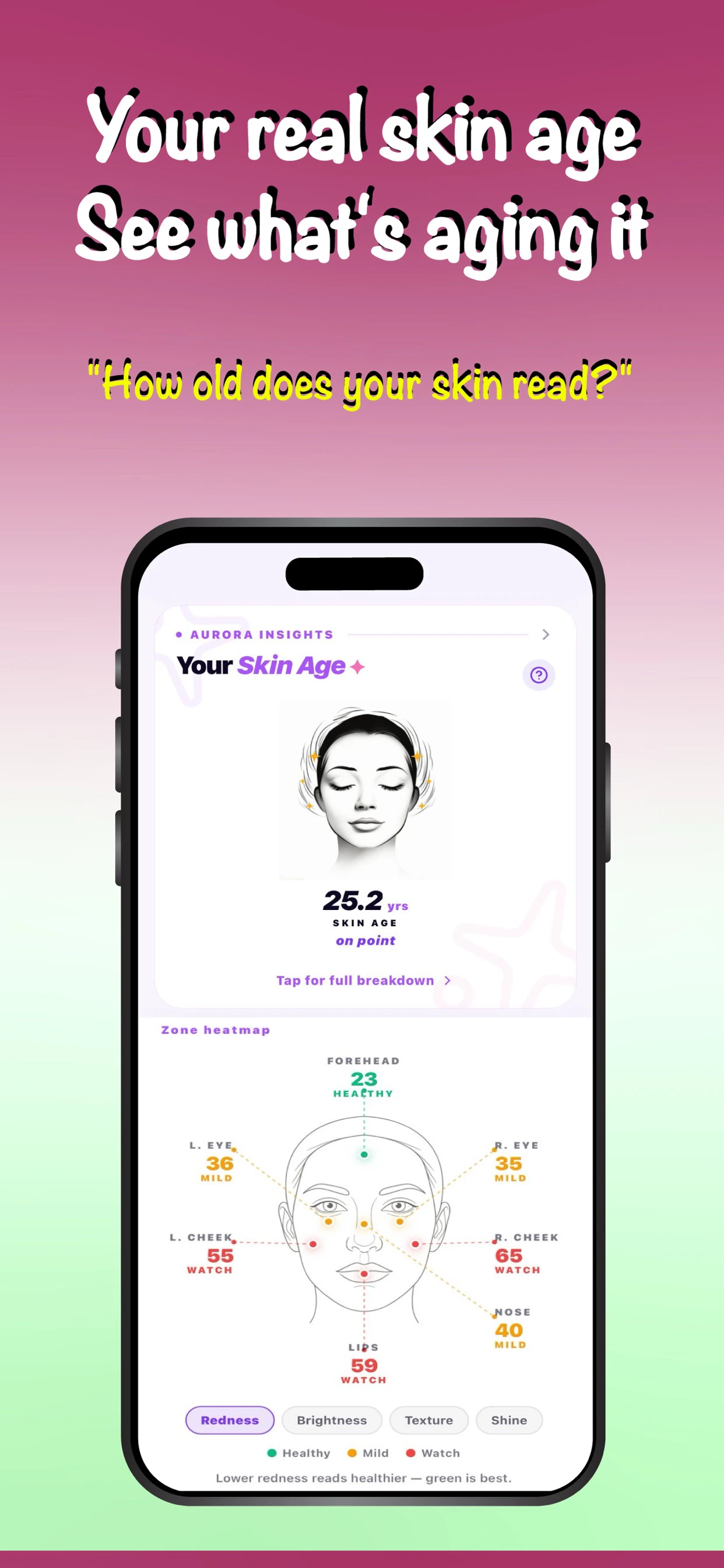
NeuroViz — AI 珠宝产品图 + 虚拟试戴(TryOnfy 近亲)↗
→ 对你是竞品情报 + 垂直延伸参考。虚拟试戴你已经在做(TryOnfy),它把场景收窄到珠宝电商的产品图工作流(修图 + 抠图 + 试戴打包卖给卖家),$29/mo 是 B 端定价。值得想:试穿 / 试戴按『垂直品类 + 电商卖家工作流』切,比通用 C 端试穿更好变现——珠宝、眼镜、手表都可复制这个模型。
值得知道
NeuroViz — AI 珠宝产品图 + 虚拟试戴(TryOnfy 近亲)↗

Textile Designer AI — AI 纹理 / 面料设计↗
→ 沾你图像生成方向,但它很垂直、很专业(面料行业 CAD)。机会不在硬刚这个专业工具,而在它暴露的长尾词矿——seamless pattern generator / repeat pattern maker 这类『无缝图案生成』需求,可以做个轻量 C 端版(给手工艺 / 印花 / 壁纸 / 服装小卖家),比专业 CAD 门槛低、受众广。
值得知道
Textile Designer AI — AI 纹理 / 面料设计↗

Spritefy — AI 游戏素材生成(Pokopia 内容线可借)↗
→ 沾你游戏内容线(Pokopia)。它本身是给独立游戏开发者的工具,对你更像『内容站选题 + 工具词』来源:pixel art generator / sprite sheet maker / game asset AI 这类词有稳定的业余 game dev 搜索。能做轻量版(专攻某一类素材,如像素头像 / 图标),或当攻略 / 教程内容站的延伸工具。
值得知道
Spritefy — AI 游戏素材生成(Pokopia 内容线可借)↗
Vidnix / Vireel — AI『定制接吻』视频(同天两个同款)↗
→ 两个同质产品同天上榜,本身是『AI kiss / hug 视频』这个病毒品类还在热的信号。沾你图像 / 视频方向、技术门槛低(套现成视频模型)、传播性强、$1 冲动付费。但要掂量:这类情感 / 擦边品类生命周期短、平台政策风险高、容易一窝蜂。当蓝海词信号收着(ai kiss video / image to video),别重仓押单一玩法。
值得知道
Vidnix / Vireel — AI『定制接吻』视频(同天两个同款)↗

2026-06-15
19 条信号Agent-Reach:让 agent 用 CLI 读取 Twitter、Reddit、YouTube、GitHub 等公开数据↗
1.1k stars/d→ 这说明 agent infra 的需求正在从“会调用工具”变成“能稳定拿到外部世界数据”。对 SEO / 竞品监控 / 内容监控来说,可以关注 multi-source agent search、social listening for agents、no API fee data access 这类关键词。
值得深看
Agent-Reach:让 agent 用 CLI 读取 Twitter、Reddit、YouTube、GitHub 等公开数据↗
1.1k stars/dNVIDIA SkillSpector:专门扫描 AI agent skills 的安全工具↗
1.1k stars/d→ 当 agent 可以安装 skills、执行脚本、读写文件后,安全扫描会变成基础设施。可以沉淀 agent skill security、MCP security scanner、prompt tool permission audit 这类工具站和内容页。
值得深看
NVIDIA SkillSpector:专门扫描 AI agent skills 的安全工具↗
1.1k stars/dAI Engineering from Scratch:从教程到可交付项目的 AI 工程路线↗
562 stars/d→ AI 教育内容已经从“讲概念”转向“从零做出可交付项目”。内容站可以围绕 AI engineering roadmap、agent project from scratch、ship AI apps 做教程矩阵。
值得深看
AI Engineering from Scratch:从教程到可交付项目的 AI 工程路线↗
562 stars/d→ agent 真正进入工作流时,不会只停留在网页聊天框。跨渠道身份、线程、路由、通知和回执会成为 agent communication layer 的基础需求。
值得深看

→ 创作者工具的机会在“进现有工作流”,而不是另做一个编辑器。Premiere、Figma、IDE、Notion 这类宿主里的 AI 插件,比独立站更容易进入用户日常。
值得深看

→ agent 产品上线后最缺的是调试和质量控制,不是 demo。tracing、evals、prompt/version 回放、异常监控会成为 B2B agent 工具链的标配。
值得深看

→ 开发团队的内容生产可以从 GitHub 事件触发:merged PR、release、issue close 都能自动生成更新。对小团队来说,这是比泛泛 AI 文案更贴近真实工作流的营销自动化。
值得深看
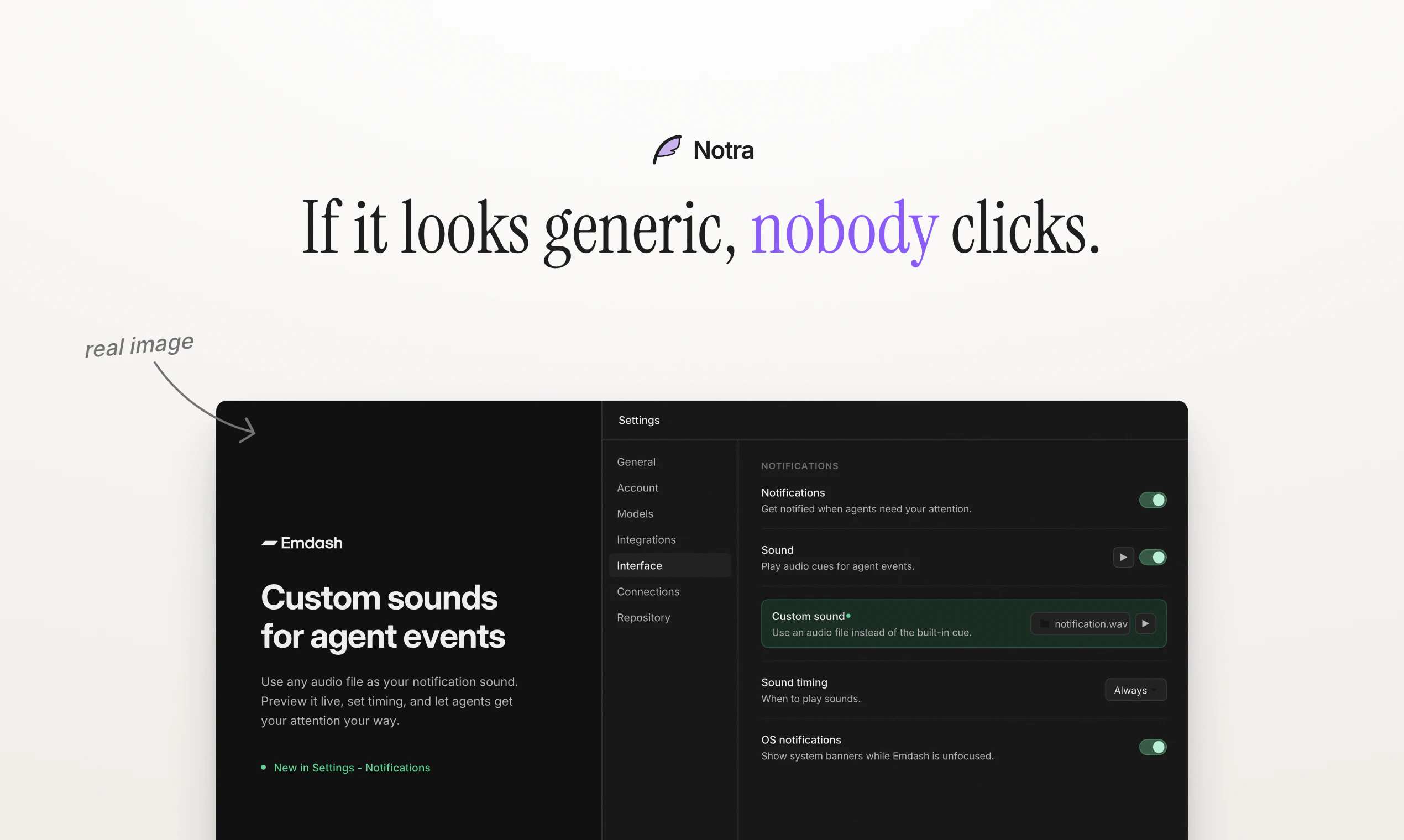
→ live website to editable mockup 是很明确的需求:竞品页面分析、落地页改版、组件抽取、设计复刻都能用。这个方向也适合和 screenshot、DOM extraction、design token 结合。
值得深看
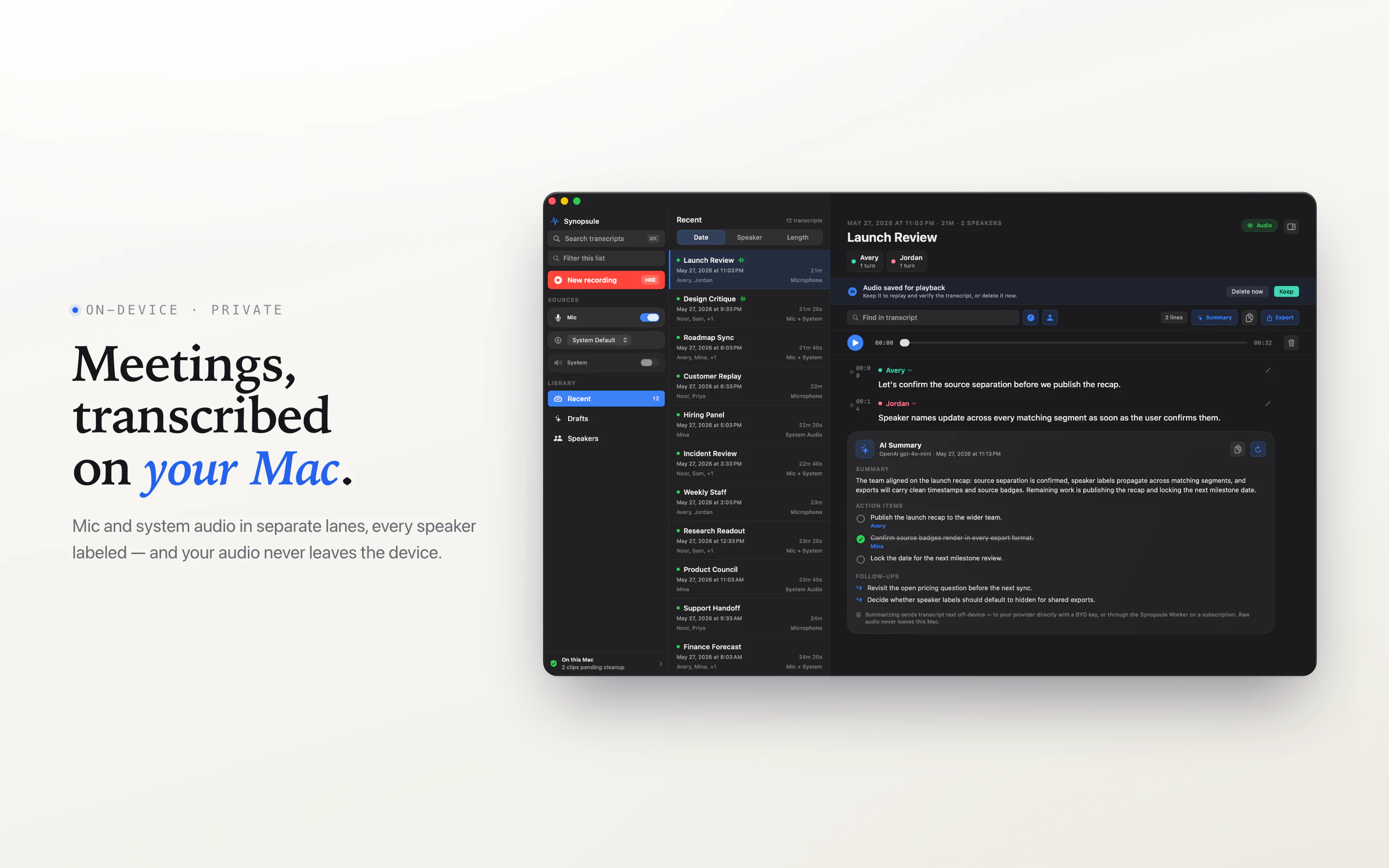
→ 会议 AI 不是只能走 SaaS 订阅。本地、隐私、低价一次性购买仍然有市场,尤其适合个人用户、敏感谈话和不想把会议上传云端的人群。
值得深看
trycua/cua:Computer-Use Agents 的开源桌面控制基础设施↗
70 stars/d→ GUI agent 会需要隔离环境、权限控制、回放、评测和跨系统兼容。独立产品可以不做完整桌面控制,但可以做某个垂直场景的 browser/desktop agent sandbox。
值得深看
trycua/cua:Computer-Use Agents 的开源桌面控制基础设施↗
70 stars/dheadroom:在进入 LLM 前压缩工具输出、日志和 RAG chunks↗
43 stars/d→ context engineering 正在成为 agent 产品的独立层。对 Codex/Claude Code 这类工具,日志压缩、上下文预算、RAG chunk 压缩会直接影响成本和稳定性。
值得深看
headroom:在进入 LLM 前压缩工具输出、日志和 RAG chunks↗
43 stars/dFigPad↗
→ 科研图不是普通 image generation,用户要的是准确、可编辑、符合论文审美。scientific figure generator、biology diagram maker、research illustration 这类词值得跟踪。
值得深看
FigPad↗

ponytail:给 Claude Code / Cursor 准备的 agent skills 和规则包↗
261 stars/d→ agent 的能力差异不只来自模型,也来自规则、技能和工作流资产。可以关注 Claude Code skills、Cursor rules、agent workflow templates 这类可下载 / 可订阅资产。
值得知道
ponytail:给 Claude Code / Cursor 准备的 agent skills 和规则包↗
261 stars/d→ “问 LLM 这是真的吗”本身不可靠,所以浏览器侧验证层有机会。可以关注 source validation、AI answer verifier、citation checker 这类关键词。
值得知道
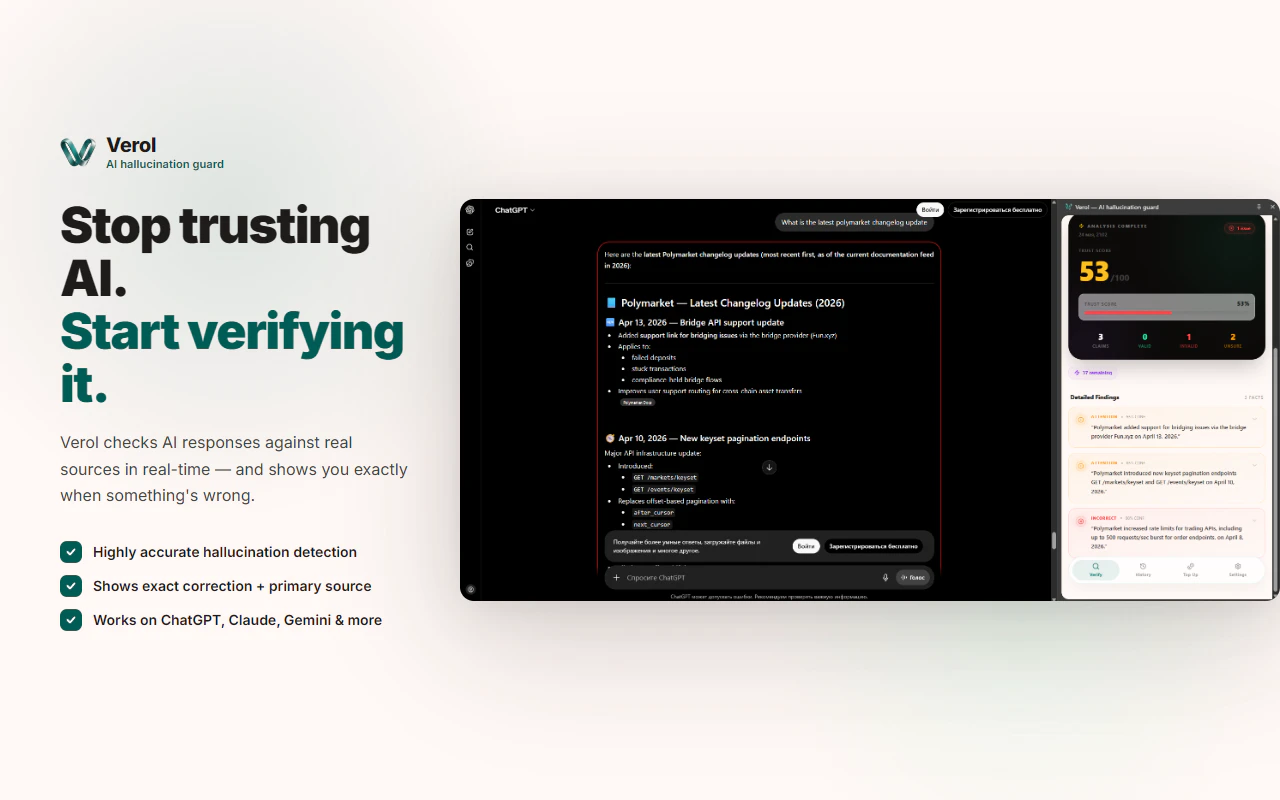
Audiomatic↗
→ 视频工具链不只缺画面生成,也缺低成本 sound design。短视频、游戏 trailer、产品 demo 都可能需要按场景生成音效和背景声。
值得知道
Audiomatic↗

Flashify↗
→ PDF to flashcards 是清晰需求,适合做学习工具站和模板页。关键在于卡片质量、章节结构、Anki 导出和不同考试场景的垂直化。
值得知道
Flashify↗

SpriteCook↗
→ 游戏资产生成可以比通用图像更垂直:sprite sheet、角色动作、tile set、统一风格、导出规格都是具体需求。
值得知道
SpriteCook↗
Sentrely↗
→ 当企业同时跑多个 agent,权限、审计、监控、版本、成本控制会集中成 control plane 需求。独立开发者可以做轻量版 agent dashboard 或 governance checklist。
值得知道
Sentrely↗

ProofWrite↗
→ AI humanizer 赛道很卷,但“humanize + verify”说明用户不只要润色,还要降低被识别风险。这个方向适合观察,不一定直接进入。
扫一眼
ProofWrite↗

2026-06-14
19 条信号NVIDIA / SkillSpector:agent skills 开始需要安全扫描↗
964 stars/d→ 这条我会优先看。agent skill 一旦能读文件、跑命令、访问浏览器,它就不只是 prompt,而是供应链入口。后续做 skill、MCP、agent 模板,都需要最基本的 lint、安全权限解释和可审计清单。
值得深看
NVIDIA / SkillSpector:agent skills 开始需要安全扫描↗
964 stars/d→ 这条很贴近 AI 前端的真实痛点:模型能写界面,但经常没有产品气质。与其每次 prompt 里说“高级一点”,不如把目标网站的颜色、排版、spacing、组件习惯和反例沉淀成 skill,让 agent 在同一套审美里工作。
值得深看
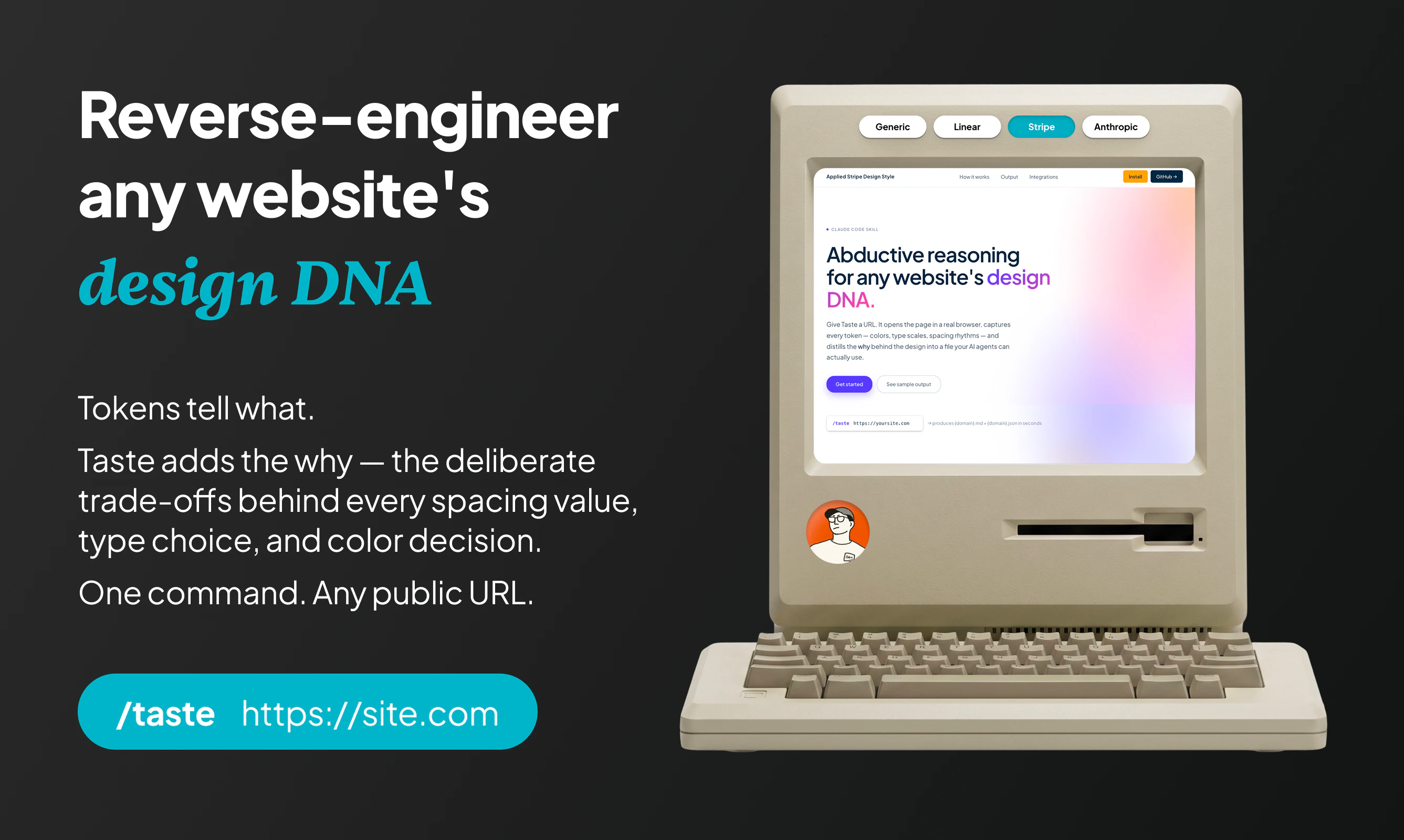
→ 这条的机会不是“聊天记录备份”这么窄,而是 AI 工作流的个人知识库。真正值钱的是跨模型统一搜索、按项目整理、敏感信息本地/加密、从旧对话里复用上下文。
值得深看

→ 如果 agent 越来越能自主跑任务,监控层会变成刚需。这里的机会不一定是再做一个客户端,而是把日志、权限、费用、失败点、可回放过程做成能让人安心接管的界面。
值得深看

Agent-Reach:让 agent 读 Reddit、X、YouTube、GitHub 这类外部信号↗
102 stars/d→ 这和 daily-web 的方向高度重合:价值不在抓到更多链接,而在把噪声社区信号变成可用判断。能做的产品不是再包一层 search,而是把来源、时间、可信度、引用证据和去重做扎实。
值得深看
Agent-Reach:让 agent 读 Reddit、X、YouTube、GitHub 这类外部信号↗
102 stars/dheadroom:LLM 上下文压缩继续从“省 token”变成工程基础件↗
89 stars/d→ 这条可以直接沉淀成工程准则:任何自动化 agent 只要会读日志、终端输出、网页正文,就应该有压缩和摘要层。否则上下文窗口再大,也会被无效文本吃掉。
值得深看
headroom:LLM 上下文压缩继续从“省 token”变成工程基础件↗
89 stars/d→ 视频工具仍然有长尾机会,但不要只写“AI video editor”泛词。更值得验证的是 talk to edit video、self-hosted video editor、Opus Clip alternative、CapCut alternative 这些带明确替代和部署偏好的词。
值得深看
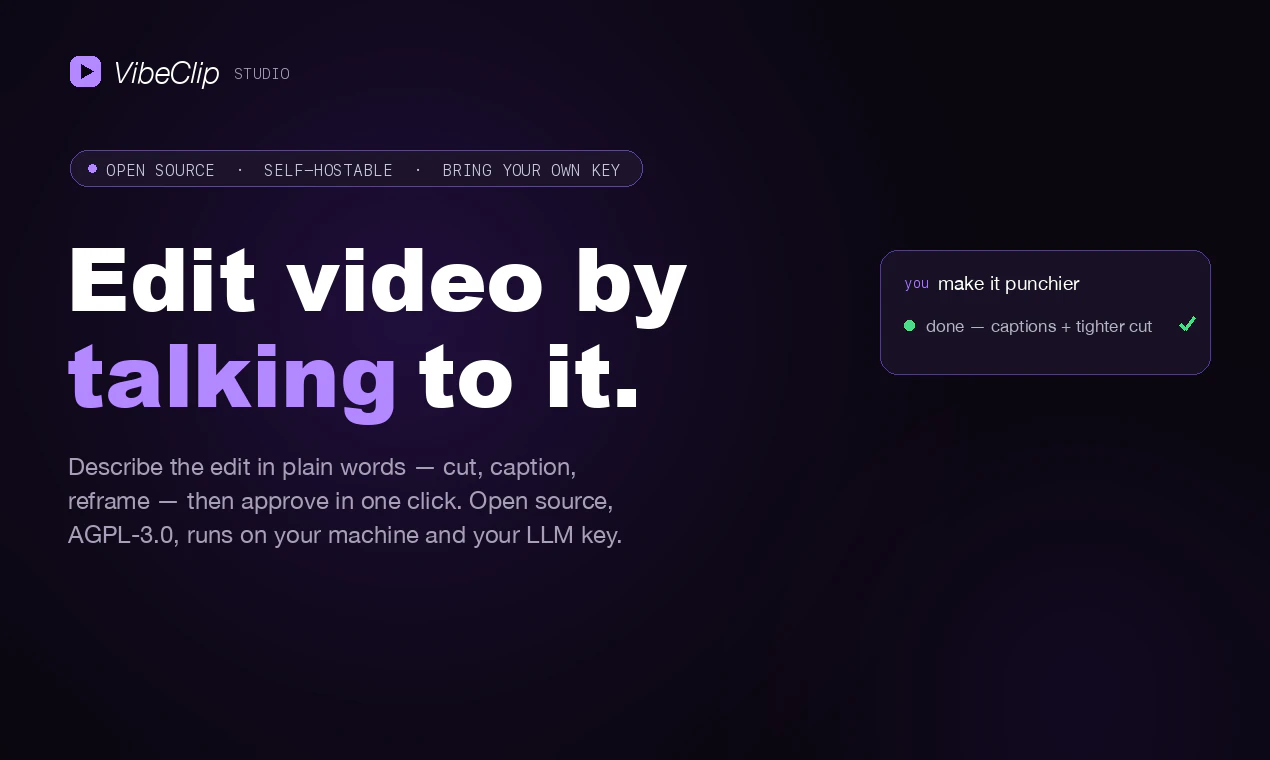
SimplePages:AI landing page builder 直接打“built to convert”↗
→ 这个方向能做,但要避开大而全建站器。更值得验证的是 AI landing page builder、built to convert、lead capture website、takes payments 这类偏转化的长尾词,用户买的不是页面,而是上线后能不能拿线索。
值得深看
SimplePages:AI landing page builder 直接打“built to convert”↗

Powabase:Postgres + RAG + agents,BaaS 开始按 AI-native 重组↗
→ 这条是强信号:AI-native app 的后端需求不只是 auth + database,还要文档抽取、embedding、工具调用、MCP 和 workflow。Supabase alternative / Firebase alternative 这类替代词很难,但 backend for AI、agent runtime backend 更像新入口。
值得深看
Powabase:Postgres + RAG + agents,BaaS 开始按 AI-native 重组↗

AI Image Translator.io:image translation 仍是很清楚的长尾工具词↗
→ 这类工具的好处是需求清楚、页面可程序化拆分:translate image text、AI image translator、image translator online,再按语言、平台、截图类型做长尾页。难点在质量和版权安全,不在概念解释。
值得深看
AI Image Translator.io:image translation 仍是很清楚的长尾工具词↗

last30days-skill:把“最近 30 天研究”封装成可复用 agent skill↗
51 stars/d→ 这个 repo 的信号在于命名和包装:用户要的不是“搜索 API”,而是“过去 30 天发生了什么”。围绕时间窗口、来源组合、输出格式做成标准任务,比泛泛提供研究能力更容易被理解。
值得知道
last30days-skill:把“最近 30 天研究”封装成可复用 agent skill↗
51 stars/dUnderstand-Anything:代码知识图继续成为 coding agent 的底层记忆↗
45 stars/d→ 这类工具的价值不在图长得漂亮,而在能不能减少 agent 找错文件、乱改边界和重复问上下文。对复杂仓库来说,代码图谱如果能喂给 Claude Code / Codex,会比纯 markdown 总结更稳定。
值得知道
Understand-Anything:代码知识图继续成为 coding agent 的底层记忆↗
45 stars/dtaste-skill:前端审美也被打包成 agent skill↗
42 stars/d→ 我会把它看成一个提醒:AI 前端质量不是多给几个渐变词就能解决,而是要把 spacing、层级、组件密度、交互状态、验收截图这些判断写进可执行规则。skill 是一种合适载体。
值得知道
taste-skill:前端审美也被打包成 agent skill↗
42 stars/d→ 这条可以直接吸收到 daily-web:任何摘要都要保留来源、时间、链接和不确定性。用户最怕的不是少一条信息,而是模型把封闭花园里拼出来的东西说成事实。
值得知道

→ 这条更像专业编辑器的 agent 化,而不是纯短视频自动化。可以盯两个页面方向:一个是 mask tracking / AI masking 这种具体能力词,一个是 browser video editor 这种部署形态词。
值得知道
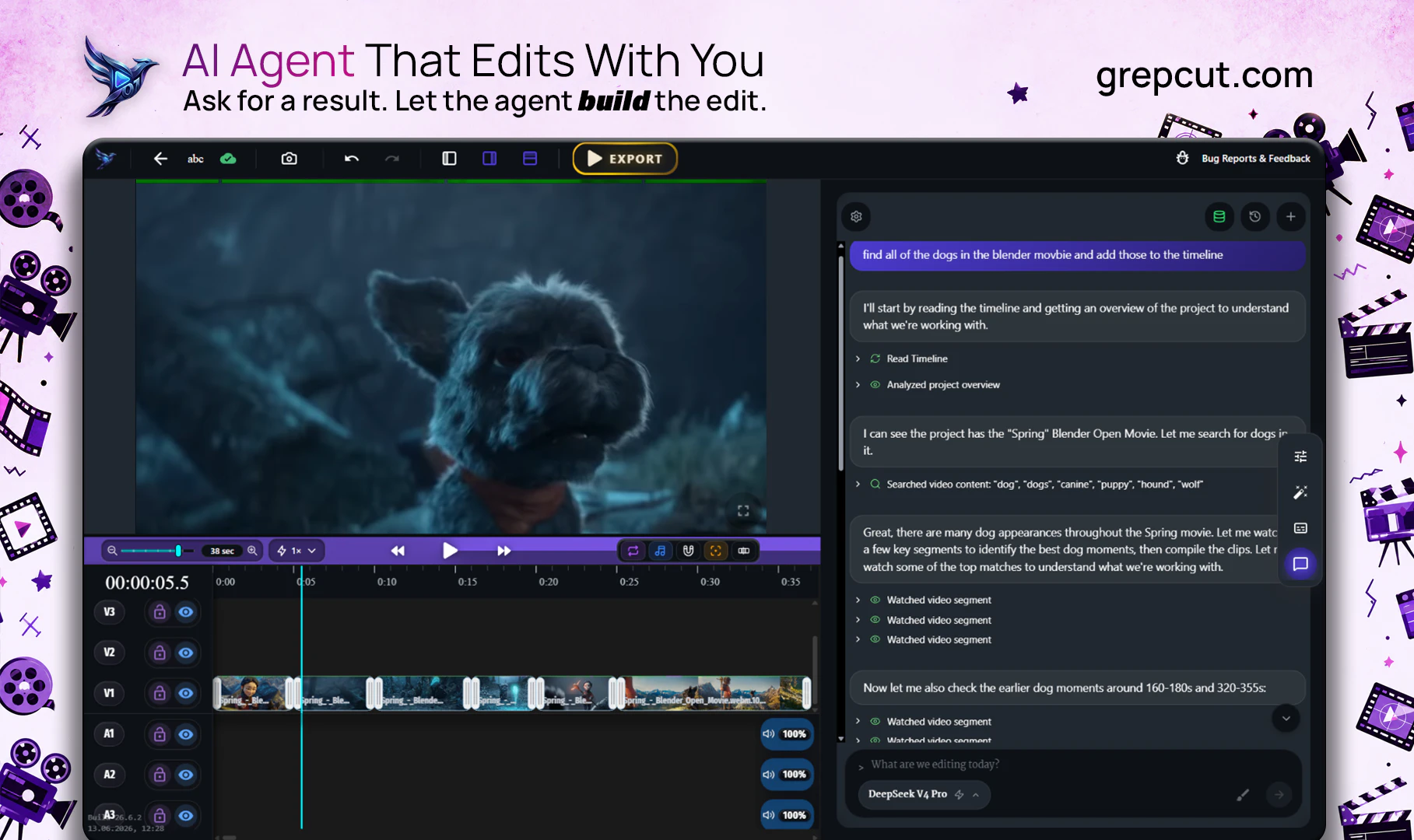
→ 这条不是让人复制素材库,而是提醒 SEO 工具可以从“帮我写一篇”改成“给我可改写的素材底库”。对内容站来说,niche assets、repurpose content、publish-ready content 这些词比泛泛 AI writer 更有差异。
值得知道

Video Character Swap | Creatii AI:视频换人从玩具图像编辑变成视频模板能力↗
→ 这条适合盯视频生成的垂直词:character swap video、AI character swap、reference image to video。只要模型能力继续提升,这些具体任务词会比 broad video generator 更容易拿到搜索意图。
值得知道
Video Character Swap | Creatii AI:视频换人从玩具图像编辑变成视频模板能力↗

AI Voice Cleaner:background noise remover 仍然是低解释成本工具页↗
→ 音频清理这种词很适合小工具站:background noise remover、AI noise cleaner、remove noise from audio 都是明确任务。竞争不会低,但页面、批处理、隐私、本地处理、垂直场景可以继续拆。
值得知道
AI Voice Cleaner:background noise remover 仍然是低解释成本工具页↗

AdControlCenter:AI ads manager 开始把 Reddit / TikTok / X 也写进投放平台词↗
→ 这条暂时更像竞品观察,但关键词值得记:AI ads manager、online ads platform、Reddit ads、spend traps。独立开发者真正需要的可能不是全平台代理,而是“小预算不烧穿”的投放护栏。
值得知道
AdControlCenter:AI ads manager 开始把 Reddit / TikTok / X 也写进投放平台词↗

2026-06-13
17 条信号agent-skills / superpowers:skill 继续变成 agent 工作流的新包装层↗
1.5k stars/d→ 如果自己的流程每天重复,就该考虑沉淀成 skill:不是写一段“请认真点”的提示词,而是把输入、限制、验证命令、失败处理写清楚。这个方向对独立开发者很实用,因为它能把一次性的经验变成可复用资产。
值得深看
agent-skills / superpowers:skill 继续变成 agent 工作流的新包装层↗
1.5k stars/dSkillSpector:agent skill 的安全扫描开始补位↗
804 stars/d→ 以后安装第三方 agent skill 不能只看效果演示,还要看它会读什么文件、跑什么命令、连什么外部服务。做 skill 市场或 agent 平台的人,也需要把权限声明和静态检查做成基础设施,而不是等用户出事再补。
值得深看
SkillSpector:agent skill 的安全扫描开始补位↗
804 stars/d→ 这条很值得看。大量小团队不是不会写爬虫,而是不想维护站点结构变化、分页、去重和字段抽取。围绕垂直数据源做 collector 模板、监控和修复,可能比再做一个通用 scraper 更容易卖。
值得深看
agentsview:coding agent session 开始需要本地可观测性↗
190 stars/d→ agent 工具链下一步会卷可观测性。独立开发者可以关注更窄的切口,比如单项目成本归因、失败会话复盘、PR 级 agent 贡献记录,而不是做一个泛泛的 dashboard。
值得深看
agentsview:coding agent session 开始需要本地可观测性↗
190 stars/d→ 这是 PH 里少数关键词非常干净的条目。AI architectural rendering 和 virtual staging 竞争不一定低,需要 Semrush 验证,但页面结构值得抄:按行业、输入类型和交付物拆页,而不是只放一个大输入框。
值得深看

→ 这类工具站方向比泛学习助手更容易落页:输入材料、输出格式、隐私承诺、付费方式都很具体。可以把 photo to Anki flashcards、PDF to Anki、local OCR flashcards 当候选词,后续再查量和竞争。
值得深看

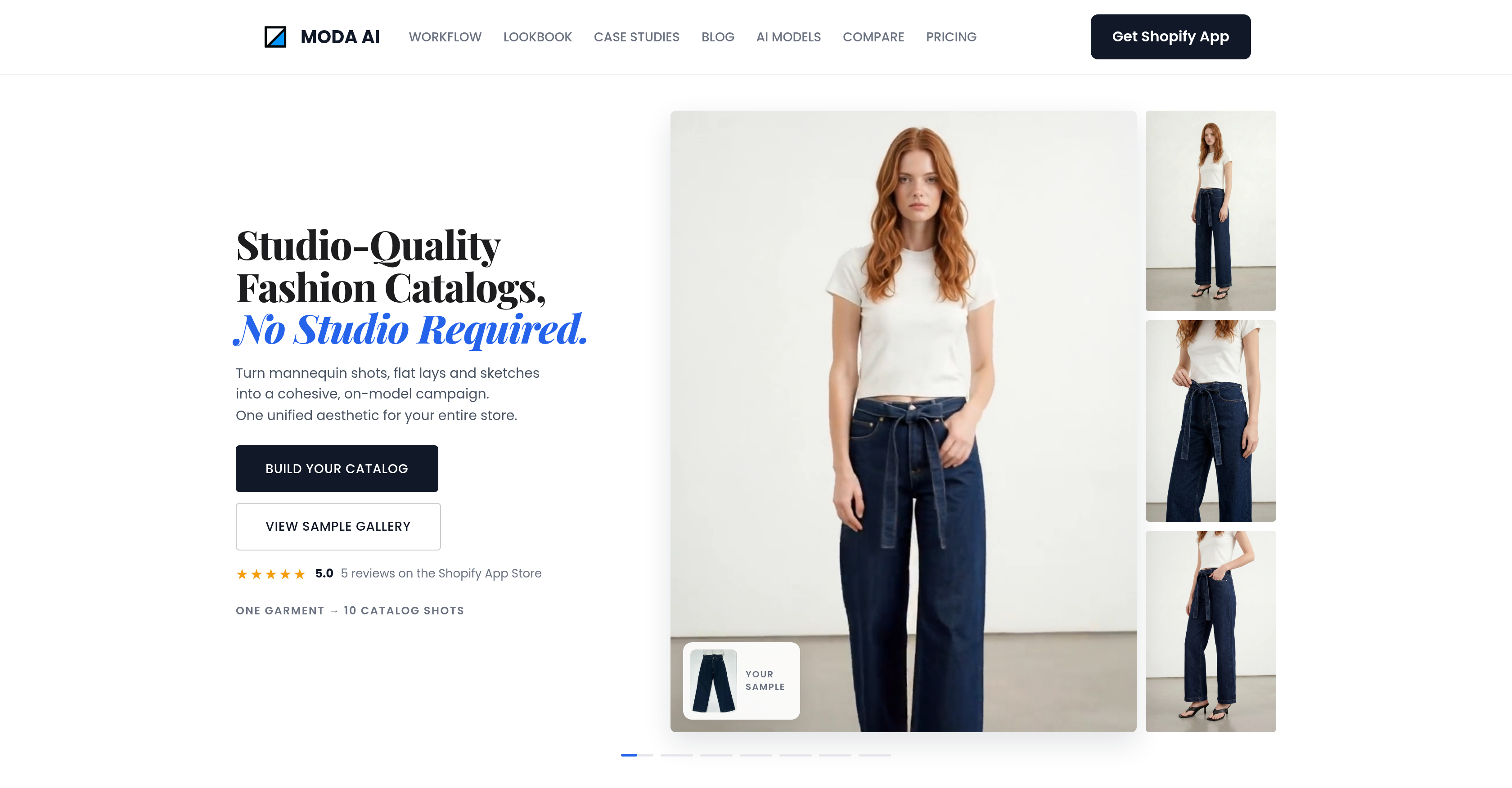
MODA AI:服装目录图从一张 outfit 到多角度 catalog↗
→ 服装图方向不要只做“AI model photo”。更具体的词可能是 fashion catalog generator、multi-angle product shots、Shopify fashion photos。要卖给商家,就得强调同一模特、一致风格、SKU 批量处理。
值得深看
MODA AI:服装目录图从一张 outfit 到多角度 catalog↗
Product Scene:商品图工具开始按 Amazon / Shopify / Etsy 交付↗
→ 这个方向仍然值得盯,因为它把图像生成和真实销售平台绑定了。真正有价值的页面不是 AI product photo 泛词,而是 Amazon product photos、Shopify product images、Etsy product photos 这种按平台拆开的长尾词。
值得深看
Product Scene:商品图工具开始按 Amazon / Shopify / Etsy 交付↗

ThumbnailCreator.com:YouTube thumbnail 继续往 CTR 工具卖↗
→ YouTube thumbnail 不是新词,但可拆空间还在:face-aware、style cloning、URL to thumbnail、CTR optimization 都能变成页面。做内容工具时,要把“更好看”翻译成点击率、首屏停留、A/B 测试这些创作者能理解的结果。
值得深看
ThumbnailCreator.com:YouTube thumbnail 继续往 CTR 工具卖↗

veridive:把 YouTube / podcast 做成可引用的 spoken web search↗
→ 这比普通 YouTube summarizer 更有空间。独立开发者可以往垂直 spoken web 做,比如创业播客检索、课程问答、投资访谈引用库。关键是引用到秒,不然只是又一个摘要器。
值得深看
veridive:把 YouTube / podcast 做成可引用的 spoken web search↗

→ 对独立开发者的启发不是去做 Vercel 竞品,而是把自己的工具首个 aha moment 压短。越是面向非工程用户,越不能让用户先读文档、配环境、选参数;先让结果出现,再解释高级能力。
值得知道

→ 模型发布越来越产品化:不只是论文和 benchmark,还要有量化、部署、示例和社区入口。做模型周边工具时,可以盯这些发布页反复出现的缺口,比如部署教程、硬件适配、eval 复现和成本估算。
值得知道

Kimi-K2.7-Code / aisuite:模型和 provider 抽象层继续并行上榜↗
127 stars/d→ 现在做 AI 工具,模型层最好留出切换空间。不是为了追新,而是防止价格、可用性、地区限制和上下文策略突然变化时,产品整个停摆。
值得知道
Kimi-K2.7-Code / aisuite:模型和 provider 抽象层继续并行上榜↗
127 stars/dheadroom:压缩工具输出和 RAG chunks,继续打 agent token 成本↗
63 stars/d→ 如果你的产品接了 agent 或 MCP,日志和工具输出不能原样丢给模型。先做结构化摘要、错误折叠、重复去除,再让模型读,往往比换更贵的模型更有效。
值得知道
headroom:压缩工具输出和 RAG chunks,继续打 agent token 成本↗
63 stars/d→ 很多 API 工具的机会不在模型更强,而在可解释性。尤其是风控、验证、审核类 API,用户要的是为什么拒绝、哪一项风险、能不能人工复核。这个角度可以迁移到图片审核、SEO 检查、表单反垃圾等小工具。
值得知道
Lynx AI:link building agent 直接打自动外链↗
→ 这条要谨慎看,不建议照着做灰色外链,但它说明 SEO agent 正在从内容生成往运营动作延伸。更干净的机会可能是外链机会发现、目录提交追踪、品牌提及监控,而不是承诺自动刷链接。
值得知道
Lynx AI:link building agent 直接打自动外链↗

Vidsteer:短视频工具继续抢“前 3 秒 hook”↗
→ 短视频脚本工具已经很挤,但按平台、行业、目标拆 hook 仍有长尾。比如 real estate reels hooks、fitness shorts scripts、LinkedIn video hooks,先查词再做模板,比做一个万能脚本框更靠谱。
值得知道
Vidsteer:短视频工具继续抢“前 3 秒 hook”↗

2026-06-12
17 条信号→ 这条比普通翻译工具更有机会,因为它卡在「产品 UI 上下文」这一步。很多 AI 翻译工具只看句子,真正出问题的是按钮长度、截图里的断行、语气和严重度。做出海工具时,localization QA / LQA 这组词值得单独验证。
值得深看

→ MCP 生态开始从「有没有工具」进入「工具能不能被 agent 信任和发现」。如果以后每个项目都有 MCP server,目录和评分层会变得很值钱,尤其是能解释为什么推荐这个工具、哪些权限风险高。
值得深看

ScrapeOps | Scraper Builder:Lovable for Scrapers↗
→ 这条和 daily-web 的痛点很近。抓网页的难点不是写第一版脚本,而是 selector、分页、反爬和结构变化。把「URL 到可运行 scraper」做成窄工具,比泛泛的网页抽取 API 更容易让开发者理解。
值得深看
ScrapeOps | Scraper Builder:Lovable for Scrapers↗

agent-skills / superpowers / pm-skills 继续占榜,skill 已经变成 agent 工作流分发格式↗
2.7k stars/d→ 这条不用再只看热度,应该看格式本身。daily-web 的跨源筛选、PH/TAAFT 关键词提取、X 引用推判断都很适合拆成 skill,因为它们有明确输入、判断规则和输出格式。越像 SOP 的东西,越适合被 agent 复用。
值得知道
agent-skills / superpowers / pm-skills 继续占榜,skill 已经变成 agent 工作流分发格式↗
2.7k stars/dheadroom、rtk、codegraph 继续说明同一个问题:agent 成本治理会产品化↗
38 stars/d→ 我会把这类工具放进 agent 基建清单。模型变强后,瓶颈不是每次都换更贵的模型,而是减少无效上下文、复用项目知识、让工具输出更适合模型读。这个方向比泛泛的「AI IDE」更容易做窄。
值得知道
headroom、rtk、codegraph 继续说明同一个问题:agent 成本治理会产品化↗
38 stars/dClaux / agentsview / Understand-Anything:coding agent session 开始需要可观测性↗
24 stars/d→ 这条最明确的需求是「我想知道 agent 刚才到底干了什么」。如果一个工具能把命令、文件改动、token、失败原因和下一步建议串起来,本质上是在给 AI 编程补审计层。
值得知道
Claux / agentsview / Understand-Anything:coding agent session 开始需要可观测性↗
24 stars/dTaste-Skill:前端审美也被打包成 skill↗
23 stars/d→ 前端质量可以被流程化,但前提是规则够具体。与其在 prompt 里写「高级、有设计感」,不如把控件尺寸、间距、真实内容密度、移动端检查和禁用套路写成 skill,让模型每次都按同一套审美闸门过一遍。
值得知道
Taste-Skill:前端审美也被打包成 skill↗
23 stars/d→ 这是直接竞品信号,但不是简单重复。它把通用 AI room redesign 往房地产 staging、去家具、家居展示图这些场景拆,说明长尾还有空间。通用词拥挤,房产经纪、空房 staging、de-staging 这种可交付场景更值得看。
值得知道

→ 这条和 GitHub 上的 agentsview 是同一个需求。Claude Code 越强,用户越想知道成本、状态、历史和失败点。独立开发者做这类工具时,本地优先和不上传会是很强的信任卖点。
值得知道

→ 本地 SEO 工具不一定要做成通用 rank tracker。更窄的切法是某个行业的市场雷达:谁新开站、谁开始投内容、谁排名突然变化。对程序化 SEO 来说,这比泛泛查关键词更像可付费情报。
值得知道

DescribeImage.io:图像描述工具开始同时打 alt text、OCR、SEO、prompt↗
→ 图像理解工具最适合走多入口长尾页。alt text、image to prompt、product image SEO、video scene notes 是不同意图,不能全挤在一个「AI image describer」页面里。
值得知道
DescribeImage.io:图像描述工具开始同时打 alt text、OCR、SEO、prompt↗

WebsitePublisher AI:让 ChatGPT / Claude 直接发布网站↗
→ 这里的新词是 MCP website builder。AI 建站不新,但「从聊天工具直接发布」会把用户心智从编辑器迁到 agent 工具链。这个方向适合观察,不要急着判断搜索量,先看是否有更多产品跟进这个词。
值得知道
WebsitePublisher AI:让 ChatGPT / Claude 直接发布网站↗

PaperClaw:科研插图也被 AI 工具站长尾化↗
→ 这是典型的高意图长尾:用户不是要一张漂亮图,而是论文、教学、graphical abstract 和可编辑 SVG。内容站如果做这类词,要把产物规格写清楚,否则会被通用图片生成工具淹没。
值得知道
PaperClaw:科研插图也被 AI 工具站长尾化↗

BeatMV / AnimeArc:AI 视频继续从单片段走向完整工作流↗
→ 视频工具的竞争点正在从「能生成」变成「能不能串起完整产物」。音乐视频、anime drama、UGC ads 都是更具体的交付物,未来更像垂直制作台,而不是单模型 demo。
值得知道
BeatMV / AnimeArc:AI 视频继续从单片段走向完整工作流↗

→ 它有意思的地方是把 AI 从「替你写」改成「逼你练」。在一堆自动生成内容工具里,这类反向定位更耐看:模型不是代工,而是反馈器和训练对手。
扫一眼

ppt-master:AI 生成真正可编辑 PowerPoint,而不是截图幻灯片↗
17 stars/d→ 这个方向值得留意,因为 Office 原生格式仍然是企业用户的交付物。做内容自动化时,能不能回到用户真正要编辑和交付的格式,比生成一张漂亮预览图更重要。
扫一眼
ppt-master:AI 生成真正可编辑 PowerPoint,而不是截图幻灯片↗
17 stars/dApex AI:牙科和 med spa 的双语 AI 前台↗
→ agent 产品越往线下服务业走,越不能只说「AI receptionist」。行业、语言、预约系统、上线周期和错过电话的损失都要写出来。这个切法比通用 voice agent 更像能卖的产品。
扫一眼
Apex AI:牙科和 med spa 的双语 AI 前台↗

2026-06-11
17 条信号→ 这条比通用 AI 图像工具更值得看,因为它把输出规格卡得很死:游戏引擎能直接用的 4x4 sprite sheet。做游戏 / 攻略相关站时,这种「小素材生成器」比大而全的 AI art 更容易打长尾词,也更容易让用户立刻理解付费点。
值得深看

→ AEO / GEO 不是一天热词,已经连续两天在 PH 和 TAAFT 出现产品。这里最适合做的是垂直版诊断页:比如只测工具站、图片站、家居设计站在 AI answer 里的可见度。具体搜索量不能凭感觉写死,但词本身已经从产品文案里验证过:AI visibility score、AI search readiness、brand AI recommendation。
值得深看
OutlierKit:YouTube 竞品分析工具,直接瞄准内容 gap↗
→ 这条很适合内容站思路:用户给一个竞争频道,你返回它漏掉的选题、爆款模式和可复制标题。英文 YouTube 这块有明确关键词,后续可以拿 Semrush 验证 youtube competitor analysis 一组词,不要只停在「YouTube 总结」这种红海词。
值得深看
OutlierKit:YouTube 竞品分析工具,直接瞄准内容 gap↗

Igly:把供应商照片批量变成平台可用商品图↗
→ 商品图这条线仍然强,但机会不在通用「AI product photo」,而在平台规格和批量工作流。Igly 这种按渠道输出 preset 的切法更适合做页面矩阵,也更贴电商用户的真实任务。
值得深看
Igly:把供应商照片批量变成平台可用商品图↗

agent-skills 和 superpowers 继续霸榜,skills 生态从个人仓库变成工程方法论↗
3.3k stars/d→ skill 正在变成 AI 编程里的新分发格式。对 daily-web 这种有明确 SOP 的工作流,最值得想的不是「再做一个站」,而是哪些流程能被打包成 skill:比如跨源情报筛选、竞品关键词提取、PH/TAAFT 选品。它的价值在于复用边界清楚,别人装完就能按同一套判断跑。
值得知道
agent-skills 和 superpowers 继续霸榜,skills 生态从个人仓库变成工程方法论↗
3.3k stars/d→ 这条适合观察 agent 产品的高端定位:不是「AI to-do list」,而是 Chief of Staff。独立开发者不太适合正面打这个市场,因为它需要深工具集成和信任;但 landing page 的命名值得学,同样功能换成角色名,用户对价值的想象会不一样。
值得知道
NVIDIA/SkillSpector:skills 开始有安全扫描器,生态进入供应链阶段↗
319 stars/d→ 这条提醒很实际:skill 不是普通文档,它会改变 agent 的行为,甚至引导 agent 跑命令、读文件、调用外部工具。以后装第三方 skill,应该像装 npm 包一样看来源、权限和指令边界。对自己写 skill 也是一样,越早把安全约束写清楚,越容易被信任。
值得知道
NVIDIA/SkillSpector:skills 开始有安全扫描器,生态进入供应链阶段↗
319 stars/d→ 对 daily-web 这种需要读 PH、TAAFT、官网 meta 的流程,这类产品说明一个需求很稳:大家不想维护脆弱 scraper,也不想每次都自己写 LLM 抽取层。可借鉴的是产品切法,把「网页到结构化数据」这个宽需求变成一个非常明确的 endpoint。
值得知道

headroom:压缩 tool 输出和日志,直击 agent token 成本↗
37 stars/d→ 这类工具可以直接进 agent 工作流评估清单。现在很多长任务失败不是模型不聪明,而是上下文里塞了太多无效命令输出;把日志摘要、文件片段和搜索结果压成可用上下文,比盲目换更贵模型更现实。
值得知道
headroom:压缩 tool 输出和日志,直击 agent token 成本↗
37 stars/dVibe coding 周边继续细分:codegraph、Understand-Anything、agentsview 都在解决上下文和可观测性↗
22 stars/d→ 这不是一个单点机会,而是一条产品带:agent 生成越多,围绕「看懂它做了什么」「压缩上下文」「复盘 session」「防止跑偏」的工具会越来越多。对独立开发者,适合从自己高频痛点切一个很窄的工具,不要上来做大而全 IDE。
值得知道
Vibe coding 周边继续细分:codegraph、Understand-Anything、agentsview 都在解决上下文和可观测性↗
22 stars/d→ 这是用户方向里的直接竞品信号,不是新蓝海。值得看的不是功能,而是关键词组合和无注册试用:AI room redesign 仍然有人新上站,但通用房间改造已经拥挤,后续更适合拆到房间类型、风格、改造预算这些长尾页面。
值得知道

→ 图像赛道仍然能做,但不能再写「AI photo editor」这种泛词。更现实的切法是明确输入、输出和渠道:截图到 launch visual、商品目录到 Instagram/Pinterest/Facebook 内容、自拍到职业图。窄场景比模型能力更重要。
值得知道

TikBreak / Reelyze:短视频增长工具正在从生成转向拆解竞品素材↗
→ 这对内容矩阵更有参考意义:生成脚本只是末端,前面更值钱的是竞品素材拆解和 hook 数据库。TikTok script generator、UGC script generator、competitor video analysis 这些词可以放进待验证清单。
值得知道
TikBreak / Reelyze:短视频增长工具正在从生成转向拆解竞品素材↗

Snappy Ads:产品照片一键生成 Facebook / Instagram / TikTok 广告图↗
→ 这条和 Igly 是同一条电商视觉链路的另一端:一个做 listing image,一个做投放素材。广告图工具最好按平台和素材类型拆,不要只写「AI ad generator」这种大词。
值得知道
Snappy Ads:产品照片一键生成 Facebook / Instagram / TikTok 广告图↗

AI Image Combiner:把人、产品、背景合成一张图,长尾词非常直白↗
→ 这类词适合做轻工具页验证。用户意图很明确,页面也容易做出免费额度和水印下载。难点不是功能,而是怎么避免和一堆通用图片编辑器撞车,可以从「商品 + 背景」「人物 + 场景」这种子场景拆页。
值得知道
AI Image Combiner:把人、产品、背景合成一张图,长尾词非常直白↗

BuildCheck / GreenPRD / MySpec:AI 时代「先别急着写代码」也被产品化↗
→ 这条和 Reddit / HN 里「vibe coded 产品长得一样、没人用」是同一个反面教材。AI 让写代码变快以后,需求判断和规格同步反而更值钱;可以把它当作自己的开发流程提醒:每个小产品先过一遍「该做 app、agent,还是 prompt」的判断。
值得知道
BuildCheck / GreenPRD / MySpec:AI 时代「先别急着写代码」也被产品化↗
VibeKit:每个 app 都配一个持久 AI agent 和托管环境↗
→ agent-native hosting 这条线值得持续看。它把「一次生成」往「长期托管、记忆、部署、BYOK」推,说明 vibe coding 产品的下一层竞争在运行环境和任务生命周期,而不是谁能生成第一版代码。
值得知道
VibeKit:每个 app 都配一个持久 AI agent 和托管环境↗

2026-06-10
9 条信号PAI 可见度(AEO)一天涌出一批工具,连传统 SEO 工具都开始喊「AI visibility」↗
→ AEO 正从概念变成有人做产品、有人会付费的品类,就在这两周集中冒出来。对 SEO 主业这是最该占的坑:词矿在 ai visibility checker、ai search visibility、geo audit 这一带,竞争度大概率还低(只是假设,待 Semrush 验)。打法上甚至能很轻——RankMesh 这种「贴 URL 60 秒出该修哪」的免费诊断页就是程序化获客的标准模板,做一个垂直版(只测某类站对 AI 的可见度)门槛不高。
值得深看
P
AI 可见度(AEO)一天涌出一批工具,连传统 SEO 工具都开始喊「AI visibility」↗
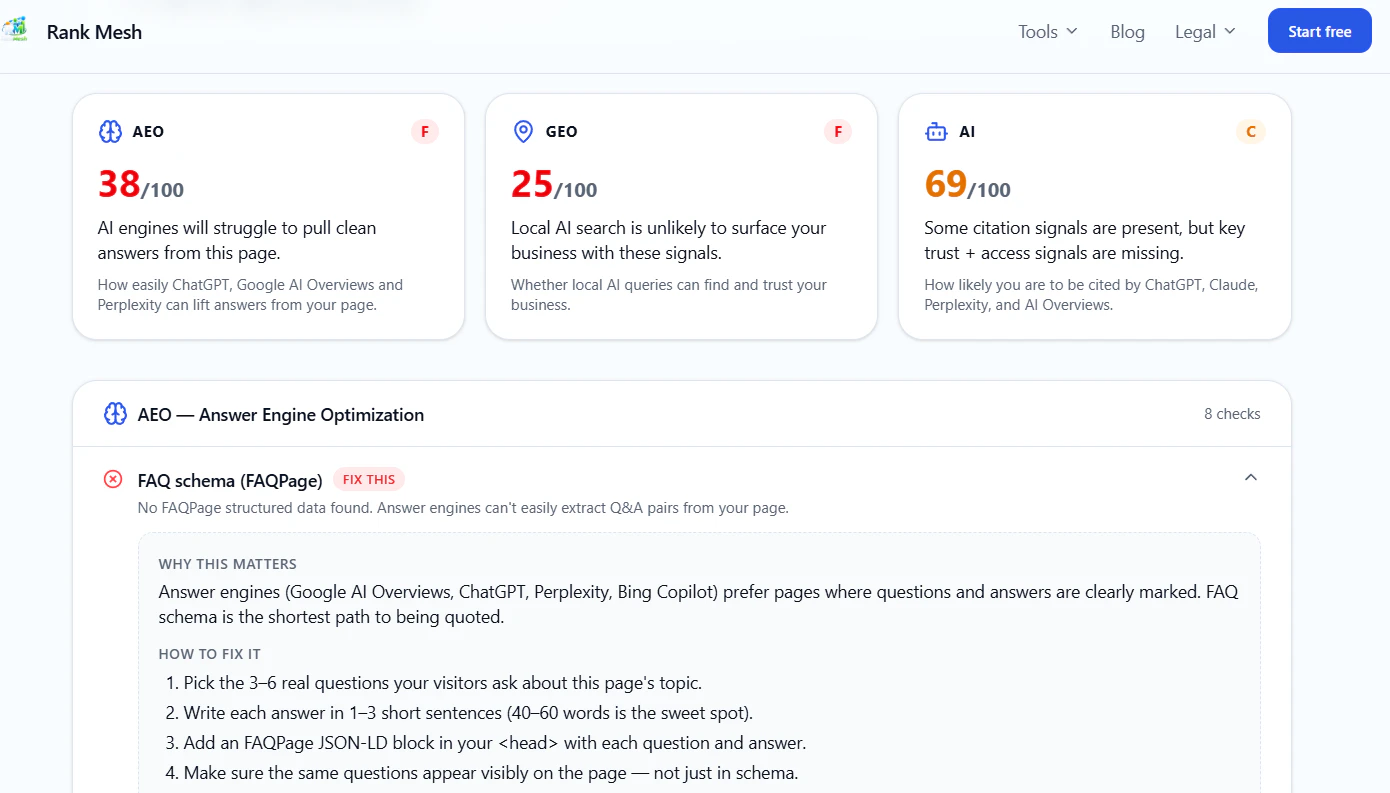
MaxAEO:监控品牌在 8 个 AI 搜索引擎里的可见度↗
→ AEO / GEO 这个方向正在从概念变成有人付费的工具品类,同一天两个独立产品撞上来就是赛道在起的信号。对 SEO 主业这是最该占的坑:「ai visibility checker」「ai search visibility」「ai seo audit」这类词还在早期,竞争度大概率比传统 SEO 词低(只是假设,待 Semrush 验)。而且它跟今天 HN 那条登顶的 HTML-first 是一条线——一头把页面做得让 AI 好抓,一头做工具帮人测「AI 看不看得见你」,监测和优化两端都能铺程序化页面。
值得深看
MaxAEO:监控品牌在 8 个 AI 搜索引擎里的可见度↗

GitHub 趋势榜被 Claude Skills 仓库刷屏,last30days-skill 单日 +2535↗
2.5k stars/d→ skills 正在变成继 MCP 之后的新分发载体——你的方法论、工作流、甚至一个垂直工具,都能打包成 skill 挂进别人的 Claude Code 里被反复调用,这是个还很新的「被发现」渠道。last30days-skill 尤其值得拆开看:它把我跑 daily-web 的活做成了几行命令就能装的 skill,与其当竞品紧张,不如读它代码学跨源综合怎么落地,再想想 daily-web 有没有「做成 skill 给别人用」的版本。
值得知道
GitHub 趋势榜被 Claude Skills 仓库刷屏,last30days-skill 单日 +2535↗
2.5k stars/dMoneyPrinterTurbo:一键 AI 生成高清短视频,单日 +1389↗
1.4k stars/d→ 对做内容站 / 矩阵的人,这是内容生产端自动化的现成参考——批量起短视频铺 TikTok、YouTube Shorts 引流,技术链路开源摆在那。但要清醒:这条赛道工具已经很多、平台对 AI 批量内容的限流也在收紧,真正的差异不在「能不能批量生成」,而在选题和分发渠道。归可借鉴打法,不是空白机会。
值得知道
MoneyPrinterTurbo:一键 AI 生成高清短视频,单日 +1389↗
1.4k stars/dPPublora:一个 HTTPS 调用发到 10 个社交平台,自带 MCP——PH 今日票王↗
→ 和 GitHub 今天 skills 爆发、PH 上一堆「给 agent 用的 VPS / 部署层 / 注册表」是同一股潮——agent-native 基础设施正在成形,大家在抢着做「agent 调用的那一层」。对独立开发者两层意思:一是这是个还新、有坑可占的品类(把某个垂直能力做成 MCP);二是反过来用,自己的矩阵站做内容分发时,这种统一发布 API 能省掉一大堆手工搬运。
值得知道
P
Publora:一个 HTTPS 调用发到 10 个社交平台,自带 MCP——PH 今日票王↗

PGapRadar:扫 PH / HN / Indie Hackers,60 秒给你的 idea 判「进 / 差异化 / 别碰」↗
→ 一天好几个「帮你找 / 验证方向」的工具,说明独立开发者「找能做的方向」这个需求很真,但工具这块已经红海。它们更大的价值其实是反向的——GapRadar 用的判据(扫 PH / HN / IH 给 enter / differentiate / avoid)跟 daily-web 线索池思路撞了,可以参考它怎么把「市场缺口」量化成一句能落地的结论。归竞品加方法参考,不是新机会。
值得知道
P
GapRadar:扫 PH / HN / Indie Hackers,60 秒给你的 idea 判「进 / 差异化 / 别碰」↗

P电商商品图自动化:Monoshoot 把 raw 商品照转 studio 级,LoomPageAI 做跨境商品图工厂↗
→ 商品图自动化跟用户的图像方向(Deroomai 系)沾边,需求稳定且付费意愿明确。但蓝海点不在「再做一个通用商品图工具」,而在绑死具体平台或品类的规格——亚马逊主图白底、某垂直站的 listing 尺寸、某类目的合规要求,这种「窄而深」才有缝。Hero AI 那条更值得记的是它证明了「拍照即上架」的转售自动化是个真实的大盘(10 万用户),但它已成熟、属竞品监控。
值得知道
P
电商商品图自动化:Monoshoot 把 raw 商品照转 studio 级,LoomPageAI 做跨境商品图工厂↗
Micro-Niche Engine:一键找到这周就能做的微利基↗
→ 这跟用户自己找蓝海词、daily-web 线索池是同一类需求——说明「帮独立开发者找能做的细分」本身就是个有人付费的市场。它的存在更像验证而不是机会:与其买它的结论,不如看它怎么用「profitable micro-niche / niche finder」这套词包装获客,这套词本身可能是个程序化内容的入口。归竞品加选题参考。
值得知道
Micro-Niche Engine:一键找到这周就能做的微利基↗

TapEdit:免费在线 AI 图片编辑器(去背景 / 消除 / 放大 / 生成填充)↗
→ 这是「免费 AI 图片工具 + 关键词矩阵」的标准打法,和用户的图像方向(Deroomai 系)沾边。它的 meta keywords 直接给了一份现成词单:background remover、object remover、watermark remover、image upscaler、generative fill 全是高需求、能程序化铺页的词。但这块是公认红海,值不值得进取决于能不能找到一个还没被打烂的细分(比如某个具体场景的 generative fill),而不是再做一个全能编辑器。
值得知道
TapEdit:免费在线 AI 图片编辑器(去背景 / 消除 / 放大 / 生成填充)↗

2026-06-09
23 条信号→ GEO/AEO 今天跨源冒头(PH 的 BrandGEO + TAAFT 的 Arobis),是个正在起量且竞争还没饱和的窗口,正中你 SEO 主业。它的白标-给代理商-按客户计费是个比纯订阅更聪明的变现模型——做一个工具,卖给一批要给客户交活的代理商。能做:免费跑分当钩子拉新,承接 `ai visibility audit` / `brand monitoring chatgpt` / `geo audit` 这类词,量级和 KD 去 Semrush 验。
值得深看

→ 这是个现成的程序化 SEO 站模型,几天就能起骨架:每个微工具一个独立 landing,靠纯前端实现(无后端成本),用大量 `xxx generator` / `xxx converter` / `xxx checker` 长尾词聚流量。它的 meta keywords(`qr code generator`、`meta tag generator`、`robots txt generator`、`image compressor`、`json editor`…)就是一张可直接拿去 Semrush 批量验的词表——这类词单个量级不大但极多、KD 通常低,适合矩阵铺量。门槛低到能立刻试,关键是选词和聚合页结构。
值得深看
Reel to Prompt:把 Reels/TikTok/Shorts 反推成 AI 提示词↗
→ 这是个现成的蓝海词矿,能做且门槛在你能力圈内。它自己 meta 里铺的词(`video to prompt`、`sora video to prompt`、`reel to midjourney prompt`、`youtube shorts to prompt`、`reverse engineer reel`)就是一张待验证的词表——假设这些是低竞争长尾(reverse/逆向类意图明确、单词量级可能几百到几千/月),靠纯免费工具 + 程序化页(每个平台/每个目标模型一个 landing)就能铺。先拿这些词去 Semrush 跑量级和 KD,别当事实,验证完再决定做不做。
值得深看
Reel to Prompt:把 Reels/TikTok/Shorts 反推成 AI 提示词↗
Arobis AI Visibility Checker:测你的网站在 AI 引擎里有多可见↗
→ 这条正中你主业,且 GEO/AEO 还在蓝海窗口。可做的就是这种「免费 AI 可见性诊断」工具站——用免费跑分当钩子,承接 `ai visibility checker` / `ai seo audit` / `how to rank in chatgpt` / `geo checker` 这类词。假设这些词正处在搜索量起量但竞争还没饱和的阶段(传统 SEO 工具站都还没补齐 AI 引擎维度),是先占坑的好时机。词和量级仍要 Semrush 验。
值得深看
Arobis AI Visibility Checker:测你的网站在 AI 引擎里有多可见↗
turbovec:基于 TurboQuant 的向量索引(Rust 内核 + Python 绑定)↗
1.8k stars/d→ 放在今天 HN「grep 够不够用」的讨论旁边看更有意思:向量检索在变得更轻更快,但对中小内容站,真正的决策是「数据量到没到非上向量库不可」。turbovec 这类降低了自托管门槛,但我现阶段更可能先用 agent 直接读 + grep,把向量库留到语义检索真的成为瓶颈再上。
值得知道
turbovec:基于 TurboQuant 的向量索引(Rust 内核 + Python 绑定)↗
1.8k stars/dtolaria:管理 markdown 知识库的桌面应用↗
829 stars/d→ 这个痛点你接得住:内容站/攻略站本质就是一大堆结构化 markdown,「本地写作 + 结构化管理 + 一键发布」这条链上还在出新品说明没有谁通吃。可做的不是再造一个 Obsidian,而是垂直到某个内容品类(比如游戏攻略/SEO 内容)的轻量编辑+发布工作流。
值得知道
tolaria:管理 markdown 知识库的桌面应用↗
829 stars/dpm-skills:100+ agentic skills 的「PM 技能市场」↗
806 stars/d→ 要观察的趋势是:skill 正在从「单个工具的扩展」变成一种通用交付格式,甚至开始有人做「skill 市场」。对我的含义有两层——一是给工具写文档时可能要同步出一份给 agent 看的 skill;二是「某垂直领域的 skill 合集」本身可能成为一种内容/流量资产。还没到动手的点,先盯着它会不会真长出分发和变现。
值得知道
pm-skills:100+ agentic skills 的「PM 技能市场」↗
806 stars/daddyosmani/agent-skills:给 AI 编程 agent 的生产级工程 skill↗
443 stars/d→ 几天能消化的提效来源:直接拆它的 skill 看哪些能并进我自己的 Claude Code 工作流(测试约束、评审 gate、上下文卫生这类)。比起从零写规范,借成熟工程师沉淀的 skill 起步更快——这类「拿来即用的工程经验」是当下最划算的学习入口。
值得知道
addyosmani/agent-skills:给 AI 编程 agent 的生产级工程 skill↗
443 stars/d→ 和今天 HN 的 performative-UI、GitHub 的 taste-skill/impeccable 是同一股反 AI-slop 的潮,正好印证你做 UI 一直坚持的方向。可借的点是它的交付形态——把设计系统打包成 agent 能直接读的 DESIGN.md + 可移植 CSS,这正是「给人也给 agent 用」的产物。对自己的项目,意味着别用默认模板,把一套 DESIGN.md 喂给 Claude Code 能显著提升输出一致性。
值得知道

→ CAD 不是你的方向,但它是今天 agent-native 这条主线的又一个样本:每个垂直专业能力都在长出「给 agent 用的 MCP 接口」。值得记的趋势含义是——当某个领域的专业工具出了 agent 接口,「用自然语言驱动专业软件」的工具站机会就打开了。先把 agent-native 当成一个要持续盯的品类,CAD 这条本身归观察。
值得知道

ppt-master:把任意文档转成可编辑的真 PowerPoint↗
12 stars/d→ 这是个典型的 AI 工具站蓝海词矿,值得用 Semrush 验一验。假设级判断:`ai ppt generator` / `document to powerpoint` 这类词搜索量应该不低(月几万级)但被 Gamma、tome 等大玩家占了头部——缝隙更可能在长尾,比如 `pdf to editable pptx`、`markdown to powerpoint`、某个垂直行业的模板化 PPT。先当假设,别当事实,去工具里跑量级和 KD 再说。
值得知道
ppt-master:把任意文档转成可编辑的真 PowerPoint↗
12 stars/dhyperframes:写 HTML 渲染视频,专为 agent 设计↗
11 stars/d→ 影响「短视频/营销视频自动化」这个产品假设。如果 agent 能用 HTML 这种它最熟的语言直接产出视频,那批量做产品演示、社媒短视频的成本会显著下降。对内容站/工具站的含义是:未来配套的营销素材(demo 视频、攻略短片)可能进入 agent 可批量生成的范畴,值得作为 agent-native 这条新品类的一个观察样本。
值得知道
hyperframes:写 HTML 渲染视频,专为 agent 设计↗
11 stars/dVoxCPM2:免 tokenizer 的多语种 TTS 开源模型↗
10 stars/d→ 影响的是「要不要做语音/有声内容」这个产品假设。开源多语种 TTS 成熟意味着出海内容站可以低成本给文章配多语种语音朗读,或做有声攻略——成本侧的门槛在塌。先记下来当技术储备,真要用时对比下它和商用 API(ElevenLabs 等)的音质与多语种覆盖。
值得知道
VoxCPM2:免 tokenizer 的多语种 TTS 开源模型↗
10 stars/d→ 这条能做但不算蓝海——`builtwith alternative` / `find websites using X` / `technology lookup` 头部被 BuiltWith、Wappalyzer 占着。可切的缝在「某个细分技术的用户名单」(比如「用了某 SaaS 的网站」做竞品挖掘/外链 prospecting)。对你更直接的用法其实是当工具用:找用了特定栈的站做外链 pitch 目标。当中等机会 + 可借的情报工具看。
值得知道

→ 和 GEO 是同一条主线的另一头:GEO 是「测 AI 怎么看你」,llms.txt 是「主动喂给 AI 该看什么」。agent-readable / AEO 还很早期,先占坑成本低。能做的是一个免费 `llms.txt generator` 工具 + 一批教学内容页(`what is llms.txt` / `how to add llms.txt`),用工具拉新、内容承接信息型搜索。词量级很可能还小(新概念),当蓝海早期信号验,别指望立刻起量。
值得知道

→ 这是泛图像生成红海里一个有差异的变现角度:图像本身不要钱,钱在实体印刷+物流。能做的话门槛在供应链(打印/裱框/履约)而非生成,未必接得住。但思路值得记——AI 工具站不一定靠订阅,绑定实体 POD(海报/相框/帆布画/贺卡)是把免费流量变现的一条路。词族 `ai poster generator` / `ai art print` / `text to poster` 可顺手留给以后验。
值得知道
→ 这条几乎是把你的 daily-web + seo-research 方法论直接产品化了——「搜索需求 + PAA + 高 CPC 反推机会」正是你找蓝海词的那套打法。它该被当成最贴身的竞品/对标盯着:看它的点子质量、出货节奏、怎么变现(订阅?导流?),既验证这套方法论有人愿意付费,也给 daily-web「线索页」怎么呈现提供参照。先观察,别急着抄。
值得知道

EzImgEditor / AI Photo Enhancer:在线提升画质、去噪、放大↗
→ 图像增强是你能做的方向,但这是红海大词——`ai photo enhancer` / `image upscaler` 头部被 Remini、Upscayl、letsenhance 这类占着,正面打不划算。真要切只能往长尾场景钻(某类老照片修复、某电商平台商品图尺寸规范、某证件照场景),用具体人群+任务把大词拆细。否则归「知道一下」就行。
值得知道
EzImgEditor / AI Photo Enhancer:在线提升画质、去噪、放大↗
ClothesChange.ai:免费免登录的 AI 换装(TryOnfy 直接同类)↗
→ 这是竞品监控不是新机会。值得记的是它的获客打法:用「免费 + 无限 + 免登录」当极致钩子做规模,再想办法变现。对 TryOnfy 的含义是要盯它怎么把这波免费流量转化——如果它纯靠广告/导流,免登录免费就是可持续的拉新护城河;如果转付费,断点就是它收口的地方,那正是差异化空间。先观察,别跟着卷免费。
值得知道
ClothesChange.ai:免费免登录的 AI 换装(TryOnfy 直接同类)↗
Zyntent:跨 AI 流量的「意图变现」↗
→ 影响的产品假设是「AI 流量怎么变现」。当传统 SEO 流量被 AI 摘要截走,谁能在 AI 交互里插入变现,谁就吃到新红利——这条路你大概率不自己做广告网络,但它点出一个方向:如果做 GEO/AEO 工具站,变现未必只靠订阅,「帮别人把 AI 流量变现」可能是更大的故事。当趋势观察,别急着下场。
值得知道
Zyntent:跨 AI 流量的「意图变现」↗
AdKit:让 AI agent 安全管理 Meta 广告的 MCP↗
→ 和今天 HN/GitHub 的 agent-native 信号是一条线:广告投放也在长出「给 agent 用」的接口。对你的含义偏观察——如果以后矩阵站要规模化投流,agent + ads MCP 可能让一个人管很多广告账户。先记着这个能力存在,等真有投流需求时它是现成的提效件,不用现在做什么。
值得知道
AdKit:让 AI agent 安全管理 Meta 广告的 MCP↗
MkAnime AI:一句提示词产出动漫分镜/短片的工作室↗
→ 这是个垂直缝隙:泛图像生成红海,但「动漫/二次元」这一垂直人群付费意愿和审美要求都明确,可能是蓝海。不过你目前没在做动漫方向,门槛在「角色一致性 + 风格 fine-tune」这种活,未必接得住。当成「垂直化是泛图像工具突围路径」的样本记下来,词族(`ai anime generator` / `anime storyboard ai`)可顺手留给以后。
值得知道
MkAnime AI:一句提示词产出动漫分镜/短片的工作室↗
Knowcast:把想法转成可视化讲解视频↗
→ 内容站邻域可做:`ai explainer video generator` / `educational video generator` / `youtube explainer videos` 这些是它自报的词。假设级判断——解释类视频需求稳定(教育/科普/YouTube 自媒体常年要),竞争中等(Pictory、InVideo 等在做但没人通吃垂直)。可做的角度是绑定某内容品类(比如把攻略/教程一键转讲解视频),把大词拆成场景词。仍需 Semrush 验量级。
值得知道
Knowcast:把想法转成可视化讲解视频↗
2026-06-08
28 条信号last30days-skill:让 agent 研究 Reddit、X、YouTube、HN 等最近 30 天内容↗
3.6k stars/d→ 这条是强信号:用户需要“近期、跨源、可追溯”的研究能力,而不是泛网页搜索。daily-web 后续也应强化 source-aware 和 time-window-aware 的定位。
值得深看
last30days-skill:让 agent 研究 Reddit、X、YouTube、HN 等最近 30 天内容↗
3.6k stars/dAgent-Reach:给 agent 接入 X、Reddit、YouTube、GitHub、B 站、小红书↗
679 stars/d→ 如果未来 daily-web 要从日报变成 agent 可调用情报层,多平台访问、反封锁、结构化抽取会成为核心资产。
值得深看
Agent-Reach:给 agent 接入 X、Reddit、YouTube、GitHub、B 站、小红书↗
679 stars/d→ 这和 HN 的 Intuned、Web Speed 形成同日共振:浏览器 agent 的下一步不是“会点网页”,而是可安装、可复用、可维护的网站技能。
值得深看

taste-skill / impeccable:让 AI 前端输出更有品味的 skill 继续上榜↗
138 stars/d→ 这对 daily-web 的 UI 也是约束:前端体验本身就是产品信号,不应交给默认模板。设计 skill 会成为 AI 工程的标准配件。
值得深看
taste-skill / impeccable:让 AI 前端输出更有品味的 skill 继续上榜↗
138 stars/dheadroom:在进 LLM 前压缩工具输出、日志和 RAG chunks↗
90 stars/d→ 这和跑日报、浏览器 snapshot 控制是同一类问题。未来 agent 工作流的质量,很大程度取决于上下文进入模型前的清洗和压缩。
值得深看
headroom:在进 LLM 前压缩工具输出、日志和 RAG chunks↗
90 stars/d→ Artifacts 周边工具是典型生态缝隙:大平台创造新格式,小团队围绕导出、播放、本地运行、版本管理做效率件。
值得深看

codegraph:给 Claude Code、Codex、Cursor 等用的本地代码知识图谱↗
68 stars/d→ AI coding 的瓶颈正在从“会不会写代码”转到“是否理解 repo 结构”。本地索引、symbol graph、blast radius 会成为刚需。
值得深看
codegraph:给 Claude Code、Codex、Cursor 等用的本地代码知识图谱↗
68 stars/d→ AI native 用户已经遇到多工具复制粘贴和上下文断裂问题。canvas 不是新概念,但 MCP + local-first 让它更像工作台而不是白板。
值得深看

→ 这与 GitHub 上的 codegraph 同日出现,说明“代码文本不够,代码地图才够”正在变成明确需求。
值得深看

Linkeddit:找 Reddit 上 ready to buy 的用户↗
→ Reddit 需求挖掘越来越拥挤,但仍是强需求。差异点可能在 query 配置、intent 分类、反 spam 和可验证转化。
值得深看
Linkeddit:找 Reddit 上 ready to buy 的用户↗
goose:可扩展开源 AI agent↗
699 stars/d→ agent 框架竞争很拥挤,单看框架本身未必是机会;但它们沉淀出的插件、权限、工作流设计值得拆解。
值得知道
goose:可扩展开源 AI agent↗
699 stars/dgoogle/skills:Google 产品和技术的 agent skills↗
461 stars/d→ 这会影响工具文档和 SOP 的写法:未来给人看的教程,也可能需要同步给 agent 看的 skill。
值得知道
google/skills:Google 产品和技术的 agent skills↗
461 stars/dCopilotKit:前端里的 agents 和 generative UI stack↗
378 stars/d→ 前端不是只嵌一个 chatbox,而是让 agent 能理解页面状态、触发动作、生成 UI。daily-web 后续若做交互分析,也可以关注这类栈。
值得知道
CopilotKit:前端里的 agents 和 generative UI stack↗
378 stars/d→ 企业 AI 培训不只是生成课程,而是把知识更新链路接上。这个思路可迁移到 SOP、技能库、内部 agent 使用手册。
值得知道

→ 视频本地化仍是强赛道,但竞争点从“翻译字幕”升级到声音、口型、语义和背景音整体保真。
值得知道

mempalace:开源 AI memory system↗
170 stars/d→ memory 方向要警惕泛概念,但它和长期项目协作、知识库迭代、个性化 SOP 直接相关,值得持续观察。
值得知道
mempalace:开源 AI memory system↗
170 stars/dwhichllm:按本机硬件实测本地 LLM↗
143 stars/d→ 本地模型选择正在变成普通用户问题。关键词可关注 local LLM benchmark、best LLM for my hardware、run LLM on laptop。
值得知道
whichllm:按本机硬件实测本地 LLM↗
143 stars/d→ 这是很好的增长打法:把产品能力包装成挑战和榜单,而不是只写功能页。对开发者工具尤其适用。
值得知道

→ AI coding 越多,测试数据和边界 case 会越重要。把 schema 直接转 mock,是小而刚的开发者工具需求。
值得知道

→ 安全 agent 的价值点在“可复现证据”而不是发现列表。这个原则可迁移到 SEO、QA、监控:发现问题必须能给复现路径。
值得知道

→ AI SEO 叙事开始和传统技术 SEO 合流。对工具站来说,结构化数据、渲染一致性、索引健康仍是底层盘。
值得知道

Edge Arena:让多个 AI 竞争,输出商业策略↗
→ AI disagree / braintrust / debate 是近期反复出现的产品表达。卖点不是“又一个聊天”,而是通过结构化反对意见提高决策质量。
值得知道
Edge Arena:让多个 AI 竞争,输出商业策略↗
Document Transcribe:手写历史文档转可搜索文本↗
→ 垂直 OCR 仍有长尾空间:历史档案、家谱、老信件、研究材料这类语境,比“image to text”更容易定位人群。
值得知道
Document Transcribe:手写历史文档转可搜索文本↗
SciFigureAI:研究想法转 scientific figure drafts↗
→ 科研可视化是 AI 图像生成里更专业的分支,用户愿意付费的点不在美图,而在表达准确、可编辑、符合论文语境。
值得知道
SciFigureAI:研究想法转 scientific figure drafts↗
Crucible AI Braintrust:专门设计来反驳你的 AI↗
→ 同一天多个 decision support 产品出现,说明“AI 赞同太多”已经变成可营销痛点。后续可以观察这个词族是否有搜索量。
值得知道
Crucible AI Braintrust:专门设计来反驳你的 AI↗
ViraFlow:把 viral videos 转成 prompts 和新 AI videos↗
→ 短视频工具正在从“生成”转到“拆解爆款并复刻结构”。这类产品的关键风险是版权/同质化,但增长叙事很强。
值得知道
ViraFlow:把 viral videos 转成 prompts 和新 AI videos↗
Hatchable:AI builds it, we run it↗
→ vibe coding 平台开始补部署和运维承诺。用户真正买的不是生成代码,而是生成后能不能稳定上线、维护、迭代。
值得知道
Hatchable:AI builds it, we run it↗
turbopuffer:10x cheaper vector search↗
→ RAG 和 agent memory 的底层成本仍在下降。对大量抓取/briefing/索引类项目,向量检索成本可能不再是主要瓶颈,数据质量和更新策略更重要。
值得知道
turbopuffer:10x cheaper vector search↗
2026-06-07
23 条信号hermes-agent:一个强调会随用户成长的 agent 框架↗
1.1k stars/d→ 我会把它当作 agent 框架观察项。真正值得看的不是口号,而是它如何处理长期上下文、工具调用、任务状态和用户偏好迁移。
值得深看
hermes-agent:一个强调会随用户成长的 agent 框架↗
1.1k stars/dlast30days-skill:跨 Reddit / X / YouTube / HN 的近 30 天研究 skill↗
1.1k stars/d→ 这条很贴 daily-web 的方向:不是再加一个信息源,而是把“多源抓取、去噪、综合判断”做成可复用 skill。后续日报生成也应该往这种研究流水线靠。
值得深看
last30days-skill:跨 Reddit / X / YouTube / HN 的近 30 天研究 skill↗
1.1k stars/dtaste-skill:给 AI 页面生成加一层审美自检↗
1.1k stars/d→ 这条和 X 上前端设计 skill 的讨论互相印证。以后让 AI 写页面时,不应该只检查能不能跑,还要有设计 QA:层级、留白、色彩和组件密度都要被显式约束。
值得深看
taste-skill:给 AI 页面生成加一层审美自检↗
1.1k stars/dgoose:不止代码建议,而是能安装、执行、编辑、测试的开源 agent↗
322 stars/d→ 这条说明 coding agent 的竞争点正在从“补全代码”转向“执行完整任务”。对开发工具来说,能不能验证、改环境、跑命令,会比单纯生成代码更重要。
值得深看
goose:不止代码建议,而是能安装、执行、编辑、测试的开源 agent↗
322 stars/dProject NOMAD:离线生存电脑,把知识、工具和 AI 打包在一起↗
309 stars/d→ 这条不是普通软件项目,而是“离线 AI 工具箱”的极端样本。它提醒我:本地优先、断网可用、资料和模型打包,会在一部分场景里比云端智能更重要。
值得深看
Project NOMAD:离线生存电脑,把知识、工具和 AI 打包在一起↗
309 stars/d→ 这条值得看,因为它代表 personal context 主动浮现的方向。不是用户问 AI,而是 AI 根据你的个人数据每天整理一份“你可能需要看的东西”。隐私和价值感会决定它能不能成立。
值得深看

Odysseus:自托管 AI 工作台↗
237 stars/d→ 这条和 X 信号互相印证:用户不一定只想要云端聊天框,也会想要能接工具、接资料、保留隐私的本地 AI 工作台。
值得深看
Odysseus:自托管 AI 工作台↗
237 stars/d→ 这条有明确使用场景:把 AI 从单独 App 拉到任意输入框。对高频写作、客服回复、代码注释、邮件处理来说,入口摩擦比模型能力更关键。
值得深看
→ 这条不是 AI,但需求很清楚:移动端轻量文件分享仍然有空间。对独立工具来说,简单、低摩擦、链接好看,有时比功能大而全更重要。
值得深看
Headroom:在内容进 LLM 前压缩工具输出、日志和 RAG 片段↗
83 stars/d→ 这条很重要。agent 系统真正贵和乱的地方,经常不是模型本身,而是上下文太脏、太长、太重复。Headroom 这类工具说明 context hygiene 正在变成基础设施层。
值得深看
Headroom:在内容进 LLM 前压缩工具输出、日志和 RAG 片段↗
83 stars/dturbovec:基于 TurboQuant 的向量索引,Rust 实现并提供 Python 绑定↗
1.6k stars/d→ 这条偏底层,适合观察 RAG / 本地检索基础设施。对上层产品来说,它的意义在于向量检索继续往更快、更轻、更易嵌入的方向走。
值得知道
turbovec:基于 TurboQuant 的向量索引,Rust 实现并提供 Python 绑定↗
1.6k stars/dopen-notebook:更开放的 NotebookLM 替代实现↗
554 stars/d→ 这条适合和 Obsidian、local-first PDF、AI 学习工具一起看。个人知识库正在从“存资料”变成“让 AI 帮你读、问、整理资料”。
值得知道
open-notebook:更开放的 NotebookLM 替代实现↗
554 stars/dChinaTextbook:小初高和大学 PDF 教材合集↗
350 stars/d→ 这条单独看不贴产品方向,但和 AI 学习、资料库、知识问答结合后有启发:高质量结构化学习资料仍然是 AI 教育工具的底座。
值得知道
ChinaTextbook:小初高和大学 PDF 教材合集↗
350 stars/d→ 这条贴 GEO 内容生产,但也很容易变成红海。可借鉴的是“从关键词到 CMS-ready 内容”的流程包装,不能直接假设它的 SEO 效果。
值得知道
→ 事实核查工具有需求,但也最容易踩“看似权威”的坑。日报里只把它当作方向观察:实时 grounding、证据链和结论置信度会是这类产品成败关键。
值得知道
Podcastor:把任意内容快速变成播客
→ 这是内容再利用方向的典型工具:文章、报告、笔记转音频。机会不在“能转”,而在声音质量、结构改写和分发到播客平台的完整流程。
值得知道
Podcastor:把任意内容快速变成播客
MkAnime AI:用提示词生成完整动漫制作
→ 动漫生成听起来大,但实际落地要看角色一致性、分镜、时长和版权风险。先作为视频生成细分方向观察。
值得知道
MkAnime AI:用提示词生成完整动漫制作
Mnemosphere:AI research workspace
→ 这类定位和 daily-web 很接近:收集资料、组织证据、辅助判断。值得看它怎么处理来源、引用、摘要和多轮研究,而不是只看“research workspace”这个词。
值得知道
Mnemosphere:AI research workspace
Linkeddit:寻找 Reddit 上已经准备购买的用户
→ 这条很贴需求挖掘,但也容易变成 spam 工具。真正有价值的做法应该是识别需求和语境,而不是自动私信骚扰。
值得知道
Linkeddit:寻找 Reddit 上已经准备购买的用户
ClothesChange.ai:照片换装工具
→ AI 换装是明确需求,但竞争也很拥挤。可以作为图像工具红海观察项,除非能找到更细的场景,比如电商 SKU、模特图或特定服饰风格。
值得知道
ClothesChange.ai:照片换装工具
ViraFlow:把 viral video 变成 prompt 和新 AI 视频
→ 这条有内容生产链路价值:先拆解爆款,再生成变体。风险是同质化,但“从样例反推 prompt / workflow”这个方向值得观察。
值得知道
ViraFlow:把 viral video 变成 prompt 和新 AI 视频
MotionGen:从真实样例出发,把一个好片段扩成完整视频
→ 视频生成工具正在从“文本到短片段”走向“参考样例到完整视频”。如果能稳定保持风格和角色一致,会比单次生成更有产品价值。
值得知道
MotionGen:从真实样例出发,把一个好片段扩成完整视频
Vdoo AI:参考已有视频生成新 AI 内容
→ reference-to-video 是值得记的词。它比 text-to-video 更贴创作者真实工作流:先有一个喜欢的样例,再让 AI 做可控变体。
值得知道
Vdoo AI:参考已有视频生成新 AI 内容
2026-06-06
25 条信号Agent-Reach — 给 agent 一双看整个互联网的眼睛,一个 CLI、零 API 费↗
683 stars/d→ 这条对你有直接的工具价值。daily-web 现在抓 Reddit 要挂 7897 代理、X 靠 Playwright 借登录态手抓,最头疼的就是墙外源的抓取成本和稳定性,而 Agent-Reach 正好把这些源的读取/搜索包成一个免费 CLI。先去扒它怎么绕各平台反爬(尤其 Twitter / Reddit),看能不能接进 scan 层替掉现在那段脆的手抓。对自费跑情报站的你,零 API 费是实打实省钱。
值得深看
Agent-Reach — 给 agent 一双看整个互联网的眼睛,一个 CLI、零 API 费↗
683 stars/dlast30days-skill — 跨 Reddit / X / YouTube / HN / Polymarket 研究任意话题的 agent skill↗
439 stars/d→ 这几乎就是 daily-web 的开源近亲,值得专门拆来看。你正卡在『跨源统一分析层』——怎么把多源信号去重、归拢、收敛成结论——而它已经把这条链跑通了。先别从零想,照着看它怎么给每个源定抓取边界、怎么把异构结果揉成一份带 citation 的东西,工程骨架能直接借。
值得深看
last30days-skill — 跨 Reddit / X / YouTube / HN / Polymarket 研究任意话题的 agent skill↗
439 stars/d→ 这条跟你做 SEO 内容站关系很近:Google 正在把「作者/发布者实体」放到更显眼的位置。它不是今天能直接抄的工具,但会影响内容站长期打法——作者身份、外部平台、实体一致性会越来越重要。先记成 SEO 基建信号,不要把 US-only 当成你现在可用的功能。
值得深看
→ 这条跟 HN 的 harness engineering 完全同频。对你最有价值的是产品形态:把「如何让 agent 不乱来」包装成可调用的中间层,而不是再做一个聊天界面。你自己的 Codex 工作流也可以借这个思路,把检查点和失败模式写得更结构化。
值得深看
→ 这条非常贴你:它把你熟悉的 SEO 选词逻辑搬到了 Google Play。虽然你现在主战场不是 App Store,但「先看需求和竞争,再决定做不做」这套跟线索池完全一致。它也可以当产品参照:一个细分市场的 keyword difficulty / naming gap 工具,未必只适用于 app。
值得深看
AEO GEO AI — 监控品牌在 ChatGPT / Claude / Perplexity 里的可见度↗
→ 这条是今天最贴你 SEO 主线的 TAAFT 信号。过去几天 llms.txt、Google Search Profiles、虚构作者被 AI 引用都在说同一件事:AI 搜索里的可见度正在变成新 SEO。你可以把 AEO/GEO 当成优先验词方向,但具体数据必须之后用 Semrush/搜索结果再验证,不能凭这个工具上榜就当成有量。
值得深看
AEO GEO AI — 监控品牌在 ChatGPT / Claude / Perplexity 里的可见度↗
Editable Figure — 把图表 / 科学插图做成可编辑 SVG↗
→ 这条挺值得看。图像工具如果只输出 PNG,很容易同质化;输出可编辑 SVG,就多了一层生产力价值。你做图像或内容工具时可以记这个方向:editable SVG generator、diagram to SVG、chart illustration 这类长尾,可能比泛泛 AI image generator 更好切。
值得深看
Editable Figure — 把图表 / 科学插图做成可编辑 SVG↗
PaddleOCR — 把任意 PDF / 图像文档转成给 AI 用的结构化数据↗
433 stars/d→ 这是做图像 / 文档类工具的现成开源底座,OCR 不用自己训。配合最近反复冒头的『本地、不上传』需求(今天 X 上 Clypra、HN 一批本地优先小工具都在涨),一个『纯本地、PaddleOCR 驱动、文档不上传』的转换工具是有轮子又有需求的组合。等你定下一个工具方向时可以深看这条。
值得知道
PaddleOCR — 把任意 PDF / 图像文档转成给 AI 用的结构化数据↗
433 stars/d开源 TTS 今天双发:微软 VibeVoice + OpenBMB VoxCPM(免 tokenizer、多语言、语音克隆)↗
216 stars/d→ 语音克隆 / TTS 在 HF Spaces 上一直是常青品类,今天连 GitHub 也双发,开源底座越来越齐。对你的意义是:哪天想做语音类出海工具(配音、有声内容、多语言朗读),不用自己训模型,拿这些底座套个干净的 C 端壳 + 投对词就能起。先归 frontier 观察,等某个站需要语音能力时这就是现成轮子。
值得知道
开源 TTS 今天双发:微软 VibeVoice + OpenBMB VoxCPM(免 tokenizer、多语言、语音克隆)↗
216 stars/d→ 这条不是让你去做 Shopify agent,而是提醒:agent 正在从「回答问题」变成「管理业务对象」。你做工具站时要提前想输出能不能被 agent 复用,比如清晰 API、结构化结果、可导出的配置,而不只是一个只能给人点的页面。
值得知道
→ 对你是图像工具底座信号。最近 HF、PH 都在冒图像编辑模型,说明「只做文生图」已经不够新,真正能落地的是可控编辑、身份保持、局部修改。你如果做图像站,选题最好围绕具体编辑动作,而不是泛泛生成。
值得知道
headroom — 喂进 LLM 前先压缩工具输出 / 日志 / RAG 块,省 60-95% token↗
83 stars/d→ 连续两天在榜,说明『喂进去之前先裁』是真热不是一日游。你跑 daily-web 打分、批量生成生图 prompt 这类活,上下文里塞的全量 snapshot 和日志最占 token——把 headroom 的压缩策略扒出来搬进自己的脚本,能直接压每天的 Claude 额度消耗。几天就能落地的提效,不用等。
值得知道
headroom — 喂进 LLM 前先压缩工具输出 / 日志 / RAG 块,省 60-95% token↗
83 stars/dCloakBrowser — 过所有 bot 检测的隐身 Chromium,Playwright 的 drop-in 替代↗
22 stars/d→ 这条是给你抓取链路的备胎。你抓 PH 要解 /r/ 跳转、抓 TAAFT 要绕 Cloudflare、抓 X 靠 Playwright,越往后反爬越紧。真哪天现在的方案被识别拦了,CloakBrowser 这种 drop-in 替代能少改代码就把指纹这关过掉。现在不急着换,先收着,等抓取开始吃 403 / 验证码再拿出来试。
值得知道
CloakBrowser — 过所有 bot 检测的隐身 Chromium,Playwright 的 drop-in 替代↗
22 stars/dGitHub 半壁江山又是 agent skill:一大批 *-skill 刷屏,连 impeccable 都在榜↗
19 stars/d→ 这是分发渠道层面的信号。agent skill 现在是 Claude Code / Codex 这类 harness 的标准插件形态,发一个好用的 skill 能蹭这波生态流量涨星。你手里其实有能沉淀的工作流——daily-web 的抓取打分、SEO 选词那套——打包成 skill 开源,是个低成本的获客 + 个人 IP 动作。先记着这个口子在变热,不是今天就做。
值得知道
GitHub 半壁江山又是 agent skill:一大批 *-skill 刷屏,连 impeccable 都在榜↗
19 stars/d→ 这条不是新概念,但贴你的增长侧。你有多个工具站,落地页诊断本身就是反复需求;如果不做产品,也可以把它当 checklist 参照,尤其是「输入 URL → 结构化诊断 → 改版建议」这套输出格式。
值得知道
→ 这条延续 06-05、06-06 的本地隐私簇,而且场景更接近真实付费:企业和个人都怕把敏感信息直接丢给 AI。你做工具站时可以记这个切法——不是「不用 AI」,而是「先本地脱敏,再用 AI」。
值得知道
→ 文档问答很红海,但「整个文件夹 + 本地 + 引用」这个组合仍然有真实需求。对你更像线索而不是立即做:如果未来做内容站,可以从 local document AI、offline PDF chat、folder RAG 这类长尾切入,先验词再说。
值得知道
→ 这条抓住了 vibe coding 的真实后遗症:原型容易,变成可维护项目难。你自己做站也经常在这个缝里工作,所以这类「从 AI 原型到生产工程」工具值得留意。比起再做一个生成器,迁移和清理链路可能更有价值。
值得知道
ScanRead + HandOCR — OCR / 文本提取工具继续冒头↗
→ OCR 是老需求,但今天的变化是更偏垂直和结构化:不是「识别文字」四个字,而是从图片、手写、文档里提取可用信息。对你做工具站,泛 OCR 太红海,值得看的反而是场景词:invoice、passport、handwriting、receipt、container number 这类对象词。
值得知道
ScanRead + HandOCR — OCR / 文本提取工具继续冒头↗
Spoken / Ownvox — 播客转录、音频转文字仍在长尾增长↗
→ 音频不是你最贴的方向,但产品模板可以借:输入媒体文件,输出结构化内容,再叠一层隐私、本地、说话人识别或摘要。真正要做时要小心红海和算力成本,先看有没有垂直词,而不是直接碰 transcription 大词。
值得知道
Spoken / Ownvox — 播客转录、音频转文字仍在长尾增长↗
Vidnix | AI Text to Video Generator — 文本或参考图转视频的工具继续扎堆↗
→ 对你是底层趋势,不是优先产品。视频工具需求真,但算力成本和竞争都比图像高。更可行的切法不是泛 text-to-video,而是像 Musecut 那样绑定一个具体用途:产品 URL 转广告、商品图转短视频、教程图转演示。
值得知道
Vidnix | AI Text to Video Generator — 文本或参考图转视频的工具继续扎堆↗
NextDoor AI — 图像编辑工具继续长尾化↗
→ 这条的价值在品类判断:图像不是一个产品,而是一堆可程序化的动作集合。你更应该做的是列动作和场景,逐个验词,而不是抽象地想「做 AI 图像站」。
值得知道
NextDoor AI — 图像编辑工具继续长尾化↗
1688-shopkeeper — 1688 AI 版开店 skill 上榜↗
29 stars/d→ 单看不重要,但它和今天 X 上『西兰花农用 Codex 管 100 公顷农场』、线索池里反复出现的电商 agent 是一类信号——agent 正往非技术的传统经营者外溢,而这些人要的是『包成某行业能直接上手的形态』。对你是选品方向的弱信号:电商 / B2B 这类你之前不碰的领域,门槛正被 agent 降低。归 watchlist,攒够印证再说。
扫一眼
1688-shopkeeper — 1688 AI 版开店 skill 上榜↗
29 stars/dDashVox — 用语音写代码 / 控制开发流程↗
→ 这条先当观察。语音写代码未必适合你日常,但「开发工具的输入方式」在变多:命令行、IDE、浏览器侧边栏、语音、手机/手表通知都有人做。真正值钱的是哪种输入能降低上下文切换,而不是语音本身。
扫一眼
DashVox — 用语音写代码 / 控制开发流程↗
ONYRI 同类暗线:Oreate AI、iSummarizer、AI Resumma 都在做内容压缩 / 生成↗
→ 这类不建议你直接冲。AI writing / summarizer 太挤,除非能绑到明确场景,比如某类文档、某个平台、某个语言市场。它更像提醒:做内容工具必须先找场景缺口,别做泛总结。
扫一眼
ONYRI 同类暗线:Oreate AI、iSummarizer、AI Resumma 都在做内容压缩 / 生成↗
2026-06-05
22 条信号headroom — 在内容喂进 LLM 前先压缩工具输出 / 日志 / RAG 块↗
2.5k stars/d→ 「喂进去之前先裁」今天在 HN 和 GitHub 同时爆,是个值得马上吸收的省钱手法——你跑 daily-web 打分、批量生图 prompt 这类活,上下文压缩能直接降成本。可以扒一下 headroom 的压缩策略,看哪些能搬进你自己的脚本。
值得深看
headroom — 在内容喂进 LLM 前先压缩工具输出 / 日志 / RAG 块↗
2.5k stars/dlast30days-skill — 一个跨 Reddit / X / YouTube / HN 研究任意话题的 agent skill↗
731 stars/d→ 这条几乎是 daily-web 的近亲——多源聚合研究。值得专门扒:看它怎么跨源抓、怎么去重合并、怎么把多源信号收敛成结论,这正是你线索池「跨源统一分析层」要解决的工程问题,有现成思路可借。直接参照物。
值得深看
last30days-skill — 一个跨 Reddit / X / YouTube / HN 研究任意话题的 agent skill↗
731 stars/d→ 这条贴你能力圈:图像 + 提示词 + 内容站,正好。「ai image prompts / midjourney prompts」这类提示词聚合是有稳定搜索的,做法可以是内容站(按场景归类提示词)也可以是工具/扩展。配合 TAAFT 那条 image-to-prompt,提示词这块今天又出现了,是图像方向里值得验词的一个细分。
值得深看
Reverse Prompt — 把图片 / 视频反推成 AI 提示词↗
→ 这条正中你能力圈,而且是连续两天印证的蓝海词矿——image to prompt / image to prompt generator 这串词值得优先去 Semrush 验量。做法你熟:图像理解 + 一个结果页,工具站或内容站都能套。这是今天图像方向里我最建议先验词的一个。
值得深看
Reverse Prompt — 把图片 / 视频反推成 AI 提示词↗
AI Image Combiner — 把多张照片融合成一张↗
→ 单一图像处理动作做成站,门槛和分发你都熟(类 remove.bg 模式)。combine images / merge photos 这类是有真实搜索的方向,连续两天上榜说明需求稳。可以跟 image-to-prompt 一起,作为图像方向的验词候选。
值得深看
AI Image Combiner — 把多张照片融合成一张↗
PaddleOCR — 把任意 PDF / 图像文档转成结构化数据↗
747 stars/d→ 这是你做图像 / 文档类工具的现成开源底座——OCR 自己不用从头训,PaddleOCR 这类直接能用。配合今天反复出现的「本地 / 不上传」需求,一个「纯本地、PaddleOCR 驱动、不上传」的文档转换工具是有现成轮子 + 有需求的组合。先记着,定方向时可深看。
值得知道
PaddleOCR — 把任意 PDF / 图像文档转成结构化数据↗
747 stars/d→ 对你是趋势参照,不是直接能抄——电商多渠道运营不在你能力圈。但它印证了今天满屏那条暗线:价值在往「agent 替人操作」迁移。你做工具站时值得想一层:你的东西未来能不能被这种运营 agent 调用,而不只是给人点。
值得知道
→ 这条对你做图像类工具是底层利好——底模越强、越开放,你在上面套垂直场景(某类图、某个具体处理)的成本越低。值得盯 Ideogram 这类开源权重模型,它们是你图像工具站的发动机。具体能接什么,等你定了某个图像方向再深看。
值得知道
→ 「pinterest alternative」这类替代词是有真实搜索量的方向,而且做法清晰——找一个大平台的公认痛点(广告多、太杂),做个干净版。你做内容站 / 图库类时可以套这个思路。这条值得验一下「X alternative」相关词的量。
值得知道
→ 这条跟今天 HN 的 Lowfat(省 token)、Reddit 那条「agent 栽在认证步」是同一簇——agent 落地的工程缝隙(安全、成本、认证)正在变成具体产品。离你能力圈不算近,但「agent 周边工具」是个在快速成形的品类,值得当观察项记着。
值得知道
→ 两个可借鉴点:一是「知名订阅工具的买断平替」是个有效切法,呼应这两天反复出现的订阅疲劳;二是定价上「一次性买断」对厌烦订阅的人是真卖点。你做工具定价时可以考虑留个买断档做差异化。
值得知道
→ 这条跟你线索池的内核一致:从用户的真实表达里提炼该做什么。它是你的间接参照(看它怎么把杂乱反馈结构化),也再次印证「反馈 / 差评 → 决策」这个方向连续多天有人在做,是稳定需求。
值得知道
→ 这类「把一件重复的网页操作自动化」是 Chrome 扩展的经典生意,门槛低、痛点真。它跟今天几条扩展(Prompt Trove、ScreenLet)一起提醒你:Chrome 扩展是你还没碰过、但门槛和分发都友好的入口品类,值得单独留意。
值得知道
AI Natural Write — 把 AI 文本改成「测不出来」的人写味↗
→ humanize ai text / ai text humanizer 是热门蓝海词,但连续冒新品说明已经在变红海——验词时要重点看竞争度,别只看搜索量。对你更可能是「内容站写这个话题」而不是「再做一个同质工具」。当心同质化是这条的关键。
值得知道
AI Natural Write — 把 AI 文本改成「测不出来」的人写味↗
Easy MCP AI — 给 WordPress 的端到端 MCP 连接器(SEO 内容向)↗
→ 贴你 SEO 主业,两个角度:一是它本身是「AI 直接产 + 发 SEO 内容」的现成链路,你做内容站矩阵可以扒它的工作流;二是「MCP × WordPress」把 agent 接进内容生产,是 AEO/agent 那条线在内容侧的落地。值得当竞品 + 方法参照看一眼。
值得知道
Easy MCP AI — 给 WordPress 的端到端 MCP 连接器(SEO 内容向)↗
Musecut — 把任意产品 URL 变成带货短视频广告↗
→ 「输入一个东西、自动出成品」是好用的产品形态。product to video / url to video ad 这类对做电商/出海的人有真实需求。离你图像主线稍远,但「URL 进、成品出」这种交互范式值得记,你做图像工具时也能借(比如输入链接自动出某种图)。
值得知道
Musecut — 把任意产品 URL 变成带货短视频广告↗
open-notebook — 开源版 NotebookLM↗
1.2k stars/d→ 对你是两层参照:一是「知名 AI 产品开源平替」这个选题方向(呼应 PH 的 Pinterest 替代)持续有效;二是如果你做内容 / 知识类工具,它是现成可拆的轮子。不是直接能变现的东西,当方法和素材看。
扫一眼
open-notebook — 开源版 NotebookLM↗
1.2k stars/d→ AI 记忆是当前明显在升温的方向。对你直接价值有限(这是给 AI 用的基建),但值得记一笔:如果哪天你做的工具想接 agent 生态,「记忆 / 上下文」是绕不开的一层。先当趋势观察。
扫一眼
CopilotKit — 给 agent 和生成式 UI 用的前端栈(React / Angular)↗
366 stars/d→ 对你是技术储备——哪天你想给工具站加个 AI 助手 / agent 交互,这类前端栈能省很多事(你技术栈正好是 Next.js / React)。当前不急用,先知道有这么个轮子。
扫一眼
CopilotKit — 给 agent 和生成式 UI 用的前端栈(React / Angular)↗
366 stars/dAI 记忆项目今天集体冒头(MemPalace / memanto / moorcheh 等)↗
227 stars/d→ 这是个明显在升温的基础设施方向,但属于「给 AI / agent 用的底层」,离你 C 端工具站较远。价值是趋势判断:记忆 + agent 是下一波基建重点,等你哪天做 agent 相关的东西会用到。先归观察,不是今天动作。
扫一眼
AI 记忆项目今天集体冒头(MemPalace / memanto / moorcheh 等)↗
227 stars/dCleanaudio — AI 去掉音视频里的背景噪音↗
→ remove background noise 是有稳定搜索的老需求,红海但需求真。对你是参照而非首选(音频不在你主线)。它跟图像那批是同一种「单点处理 + 在线工具」的生意模板,模板可复用、品类可换。
扫一眼
Cleanaudio — AI 去掉音视频里的背景噪音↗
TotalMedia — 云端 AI 视频增强(给创作者)↗
→ 跟 Cleanaudio 一样属于「单点媒体处理 + 在线工具」模板。video enhancer / video upscaler 有量但竞争重,且视频处理算力成本比图像高。对你更像参照:印证这个产品模板有效,但具体做哪个细分要挑算力扛得住、竞争没那么狠的。
扫一眼
TotalMedia — 云端 AI 视频增强(给创作者)↗
2026-06-04
20 条信号→ 这条正好踩在你能做又嗅着蓝海的点上。它做的是 GEO / AEO(让品牌在 AI 答案里被引用),还很早,meta 关键词里 GEO、Generative Engine Optimization、AEO、SEO para IA 都直接写出来了——说明这批人已经在抢这组词,但整体竞争还浅。你做英文 SEO 工具站,完全可以做一个『查你的站在 ChatGPT 里怎么被引用』的轻量工具吃英文这块空白(naia 在做葡语),但别信感觉,先拿 Semrush 验 generative engine optimization / answer engine optimization / ai visibility 的量和 KD 再决定。
值得深看

→ 典型的『贴 URL 出报告』免登录工具,正是你能做的形态——零摩擦获客、天然适合程序化页(每个被审的站都能生成一个落地页)。值得抄的两点:一是免登录 + 0-100 分这种钩子转化率高;二是它把『AI 搜索就绪度』也塞进审计里,跟上面 naia 是一个方向(SEO 工具都在往 AI 搜索靠)。它 H1 喊的是 ecommerce seo audit / product schema / core web vitals,这组词你可以拿去 Semrush 看看有没有比通用 seo audit 更好切的长尾。
值得深看
→ 这就是你最熟的『一个动作 × 一组词 × 免费引流』打法,门槛完全在你能力内(你有生图/视觉能力,alt 文本只是 vision 模型加个 prompt)。它 meta 关键词扒得很干净:alt text generator、image alt text、seo alt text、automatic alt text、image accessibility——这组词意图明确、商业价值清楚(站长 + 电商刚需),值得直接拿去 Semrush 验一下 alt text generator 的量和竞争度。能做、嗅着像个有真实需求的缝。
值得深看

→ 这是工具站里最古老也最稳的一类——font generator 这组词搜索量极大、长尾无限(cursive font / bubble font / instagram fonts 每个都能开一个程序化页),而且纯 Unicode 转换不烧任何 AI 成本。它 meta 里堆的词(cute font generator、aesthetic font、cursive font generator、instagram fonts)就是现成词矿。坦白讲这词矿不算蓝海、老玩家多,但胜在零成本、长尾够散,适合当你练程序化 SEO 铺页的练手项目或流量站补充,别当主力。该不该碰看你有没有富余精力,碰之前 Semrush 扫一遍竞争度。
值得深看

PatchDesign.AI:用 AI 设计定制刺绣徽章的单点站↗
→ 这是今天最对你胃口的一条:把通用生图能力锁进一个极窄的具体物件(custom patches),免费引流,背后接实物生产变现。门槛完全在你能力内(你有 deroomai/tryonfy 的生图栈,做 custom patch generator 就是换 prompt + 落地页)。它真实在打的词是 custom patch design / ai patch designer / embroidered patch,这类『AI 设计某种实物』的词意图强、买家明确、还没被卷烂。该不该碰:先 Semrush 验 custom patches / patch maker 的量,如果有量,这种『生图 + 实物垂直』是你能直接复刻的形态,蓝海只是嗅觉、待验。
值得深看
PatchDesign.AI:用 AI 设计定制刺绣徽章的单点站↗

Restore Old Photos.pro:修复老照片的单关键词工具↗
→ 又一个『一个动作一组词一个站』的样本,跟 PatchDesign 一个逻辑、也是你能做的。restore old photos / old photo restoration / colorize black and white photo 这组词需求真实、情感价值高(修复家人老照片),付费意愿也在(它直接收 $9.9)。你有生图能力,复用做这种修复类工具边际成本低。注意这词不算冷门、老玩家有,得靠更好的免费额度或更细的长尾(restore torn photo / colorize old photo)切。碰之前 Semrush 验量和 KD。
值得深看
Restore Old Photos.pro:修复老照片的单关键词工具↗

headroom:喂 LLM 之前先压掉 60-95% 的 token(当天第一)↗
3.1k stars/d→ 它连着两天都在榜,说明『AI 成本』这条暗线还在热。对你那些要吞大块文本的批量活——daily-web 打分得整份读 snapshot、以后做站内 RAG 问答——这种『进模型前先压一道』的中间件是现成的省钱杠杆。落地很轻:有 proxy 和 MCP 两种接法,可以先在 daily-web 打分流程里小范围试、实测一下 token 到底省了多少,别光信它 readme 的数字。归可复用工程资产,想压成本时优先试。
值得知道
headroom:喂 LLM 之前先压掉 60-95% 的 token(当天第一)↗
3.1k stars/dlast30days-skill:让 agent 跨 Reddit / X / HN 扒一个话题再给你结论↗
199 stars/d→ 这条对你做 SEO 找蓝海词其实比表面看着更值。你现在挖选题靠手动翻 Reddit、看 daily-web 这些源,本质就是『跨平台扒一个话题的真实讨论再收敛』——这个 skill 把这步打包成一条命令,还带出处不至于让我瞎编。我会拿它来干两件事:一是验证某个候选词题材在社区到底有没有人在聊(需求验真),二是给内容站起稿前先摸清楚大家真正卡在哪。它跟 daily-web 自己的 scan 思路高度重合,可以反过来当参照,看它的源覆盖和去噪比我手写的强在哪。归可复用的研究资产,下次摸新方向时直接上。
值得知道
last30days-skill:让 agent 跨 Reddit / X / HN 扒一个话题再给你结论↗
199 stars/dPaddleOCR:把 PDF / 图片文档转成结构化数据喂 LLM↗
141 stars/d→ 给你内容站和数据处理补上『非文本素材』这一环。你做攻略站要扒的资料、或者以后想把一堆扫描件 / 截图 / PDF 喂进模型做问答时,OCR 把图里的字抠成干净结构化文本是绕不开的第一步。它跟昨天那条 markitdown 是一套连招:图片 / 扫描件 → OCR → markdown → 进模型。不用现在动,记进工具箱,遇到『素材是图不是字』的活直接用。
值得知道
PaddleOCR:把 PDF / 图片文档转成结构化数据喂 LLM↗
141 stars/d→ 这是个我没想到但很妙的切入角度,关键词靠 snapshot/描述提炼(它部署在 Streamlit、无 SEO meta 可抓,关键词为降级提炼,待验)。它戳的痛点很真实——一堆人用 AI 糊了个站,自己也知道哪里不对但说不出来。你做工具站可借这个『把模糊焦虑变成可量化诊断』的思路,但它本身是个 Streamlit demo、没在认真做 SEO,更像个 side project。归角度参考、不是直接能抄的成品,真要做得自己定义『AI 感信号』并解决线上爬取成本。
值得知道
→ 这条对你是工具参考多过新机会——它干的是 Semrush 那类活,你本来就在用 Semrush 镜像查词,不会再去做一个同类。真正值得记的是它的拼装思路:把 Autocomplete + Trends + Search Console + OpenPageRank 这些免费数据源缝成一个能用的关键词工具,成本极低。你自己写选品脚本时可以抄这套数据源组合,不用都靠付费 API。归工具/方法参考。
值得知道
→ 标 🏢 是因为主名带 Gemini,但实质是个 wrapper——这反而是值得你看的点:它就是『蹭一个大厂模型名字 + 做程序化 SEO 吃这个词的流量』的典型打法,meta 关键词 text to video / image to video / native audio 全是高量词。对你:做不了它的视频生成盘子(成本高、卷),但这套『傍大厂模型名 + 免费档引流 + 程序化页』的玩法可以记进选品脑子,挑一个你 hold 得住成本的具体动作(比如某种图像生成)复刻。归打法参考、品类监控。
值得知道
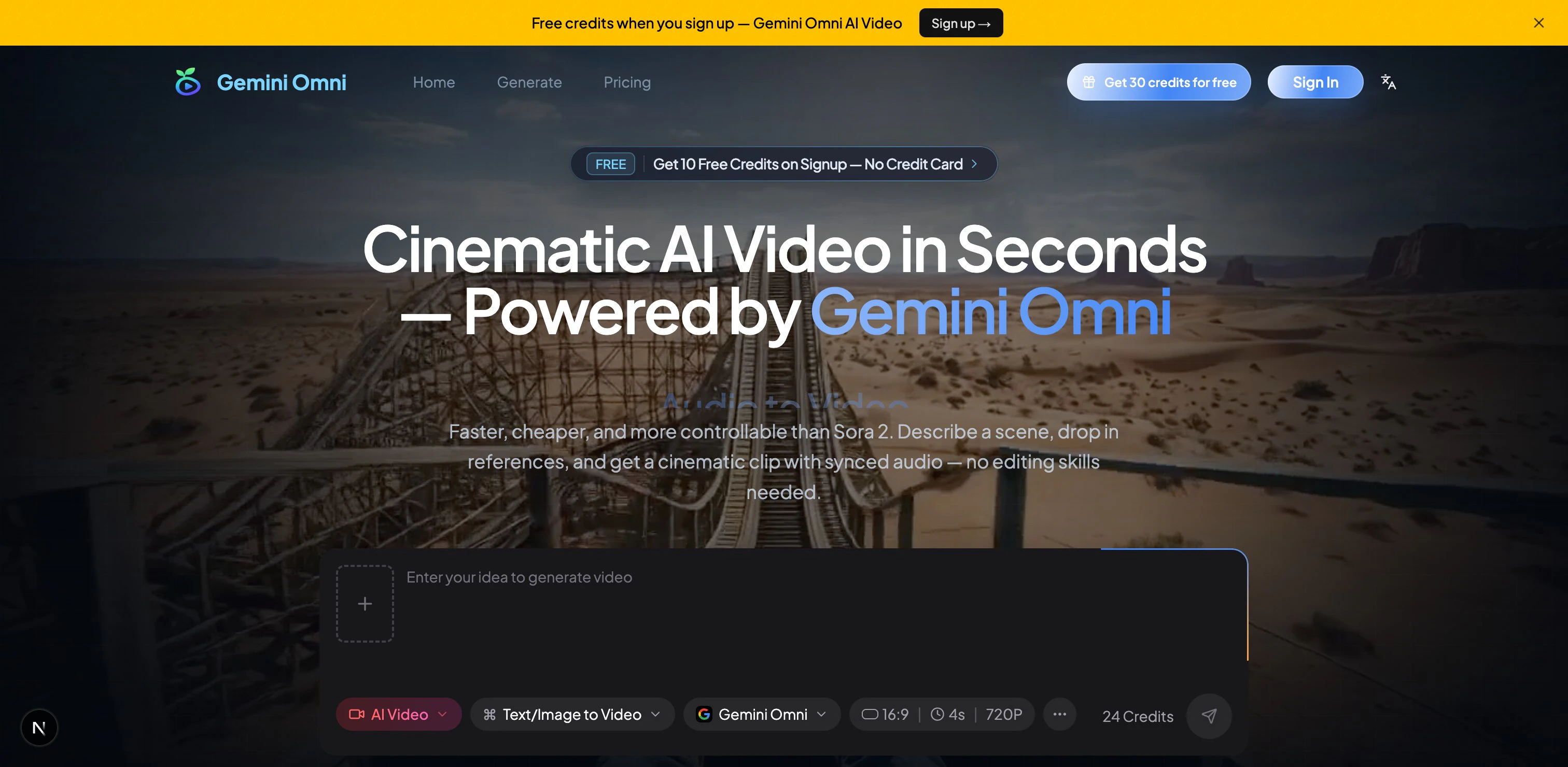
Clearfy:AI 检测 + 把 AI 文本改成人话的 humanizer↗
→ humanize ai text / ai humanizer / ai detector 是过去一年最热的内容类词矿之一,需求是真的大(学生 + 内容农场刚需),你做内容站、本身天天跟 AI 文本打交道,技术门槛也低(接个改写模型)。问题正好相反——它太热了,玩家一堆、词竞争度高,今天这个 Clearfy 也只是又一个入场的。所以这条对你是『能做但要慎入』:值得拿 Semrush 看一眼 ai humanizer 现在的 KD,多半已经红海,除非你能找到更窄的切口(某个语种、某个学科)。归能做但偏竞品监控。
值得知道
Clearfy:AI 检测 + 把 AI 文本改成人话的 humanizer↗

Uramaki:一句话生成整套社媒内容(图 + 文案)↗
→ 它把图文生成打包成『社媒内容生成器』,meta 关键词扒得很清楚:ai social campaign generator、social media content、prompt to campaign、instagram content。你有生图 + 文案能力,做得了这个形态,且『某平台内容生成器』这类词长尾极多(instagram caption generator / linkedin post generator 各是一个站)。但通用『社媒内容生成器』赛道很挤,建议不要做大而全,挑一个具体平台 + 具体内容类型的长尾切入。拿 Semrush 验某个细分词(如 instagram carousel generator)再决定。
值得知道
Uramaki:一句话生成整套社媒内容(图 + 文案)↗

VidFlux:照片转电影感视频的 photo-to-video 工具↗
→ ai photo to video / photo to video generator / image to video 是个量大需求真的词矿(跟上面 PH 的 Realty World AI 是同一组词的不同垂直)。你能不能做取决于成本——视频生成单次推理比生图贵得多,免费档烧钱快,做之前得算清楚单位经济。它落地页直接拿 /ai-photo-to-video 这个精确词做页面,是程序化页的标准操作值得抄。对你:词有量但成本是真门槛,归能做但要先算账、品类监控。
值得知道
VidFlux:照片转电影感视频的 photo-to-video 工具↗

AI Thesis Writer:给学生写论文初稿的垂直写作工具↗
→ AI 写作工具整体红到发紫,但它选了一个很窄的垂直(thesis / dissertation)切进去,这正是值得学的点——别做通用 ai writer,做『给某类人写某种文档』。thesis writer / dissertation writing / academic writing 这组词付费意愿强(学生愿意花钱)。你做内容站、技术上做得了这种垂直写作工具,机会在于继续往下切(某个学科的论文、某个国家的格式要求)找更细的缝。能做,归内容类选品池,拿 Semrush 验细分词后再说。
值得知道
AI Thesis Writer:给学生写论文初稿的垂直写作工具↗

Natiad:用 AI agent 跑全自动 SEO(自动发博客)↗
→ 这条对你是方向信号、不是新机会——它干的正是你自己在 daily-web 做的事(全自动内容 + 程序化铺页),属同路竞品。值得看两点:一是它把『在 Google 排名』和『被 ChatGPT 推荐』并列当卖点,又一次印证今天 PH naia 那条 GEO 暗线——SEO 自动化都在往 AI 搜索加码;二是 $97/mo 的定价说明『全自动 SEO 内容引擎』有人愿意付费,但这是给别人代运营的生意,跟你自建工具站不是一条路。归竞品/方向监控,你借它印证自己自动化方向没走偏就够了。
值得知道
Natiad:用 AI agent 跑全自动 SEO(自动发博客)↗

open-notebook:开源版 NotebookLM↗
212 stars/d→ 对做内容站的人是一个可自部署的资料消化层。NotebookLM 那套『把一堆资料丢进去、它帮你交叉问答和提炼』很适合写攻略 / 长文前的资料整理,开源版意味着可以接自己的模型、不受额度和隐私限制。我现在的资料整理还停在文本文件 + 手动读够用,所以先 watchlist;真到了要批量消化大量参考资料起稿时,再看它值不值得搭起来。
扫一眼
open-notebook:开源版 NotebookLM↗
212 stars/dAgent-Reach:一条 CLI 让 agent 读遍 Twitter / Reddit / YouTube,零 API 费↗
6 stars/d→ 信号还很弱(票数低),但方向贴你的痛点所以记一下。你跑 daily-web 那几个 scan 现在是各写各的、还得自己维护代理和绕反爬,Agent-Reach 把多个平台的读取统一成一条命令、还省 API 费,正好对上『少维护点抓取脏活』的需求;而且它把小红书 / B 站也覆盖了,万一以后做面向中文用户的内容能用上。星太少先别当回事,扫一眼记下来,重构 scan 层时拿来跟 Scrapling 一起比。
扫一眼
Agent-Reach:一条 CLI 让 agent 读遍 Twitter / Reddit / YouTube,零 API 费↗
6 stars/d→ 这条对你偏弱信号、相关度低,归一眼带过。它的价值在于演示了一个套路:把通用能力(照片转视频)锁进一个具体垂直(房产中介)+ 一组具体词(real estate video / property video)。你做不了房产这个本地关系生意(中介客户难触达),但这个『通用图像能力 × 垂直场景 × 长尾词』的拆法跟 WriteAlt、PatchDesign 一类是同一逻辑,记一笔思路就行,本身不值得碰。
扫一眼

2026-06-03
10 条信号headroom:喂 LLM 之前先压掉 60-95% 的 token↗
3.5k stars/d→ 正好踩在今天 HN/Reddit 那条 AI 成本暗线上。对你那些要吞大块文本的批量活——daily-web 打分得读整份 snapshot、以后做站内 RAG 问答——这种『进模型前先压 token』的中间件能直接砍成本。落地很轻:它有 proxy 和 MCP 两种接法,可以先拿 daily-web 打分流程小范围试、量一下 token 真省了多少(正好呼应 Reddit 那条『挑一个工作流端到端量化』)。归可复用工程资产,想省钱时优先试。
值得知道
headroom:喂 LLM 之前先压掉 60-95% 的 token↗
3.5k stars/dmarkitdown:微软的『各种文件转 Markdown』小工具↗
2k stars/d→ 给你内容站和数据处理的现成砖。你做攻略站、处理素材、或以后想把一堆文档/PDF 喂进模型做问答时,markitdown 把杂格式统一成干净 Markdown 这一步省事又稳。跟上面 headroom 是一套连招:脏文件 → markdown → 压缩 → 进模型。不用现在动,记进工具箱,遇到『把一堆非文本素材喂 LLM』的活直接用。
值得知道
markitdown:微软的『各种文件转 Markdown』小工具↗
2k stars/dScrapling:自适应 + 反爬的 Python 抓取框架↗
1.1k stars/d→ 这条直接贴你的数据抓取活。daily-web 那 6 个 scan 脚本、还有游戏攻略站要扒的数据,现在是各写各的 + 自维护代理池/curl_cffi 绕 CF。Scrapling 把『自适应 + 反爬』打包,值得评估能不能替掉你部分手写抓取逻辑、少维护点绕反爬的脏活(你 TAAFT 那套 curl_cffi 指纹就是典型痛点)。归可复用工程资产,下次重构 scan 层时拿来比一比。
值得知道
Scrapling:自适应 + 反爬的 Python 抓取框架↗
1.1k stars/d→ 契合度中等、你做不了原样的(你是 web SEO、没有 mobile app,ASO 不是你的主场)。但两点值得看:一是它的打包思路——『关键词研究 + 本地化元数据 + 营销站 + 资产』一站式喂给某一类开发者,这种『给细分人群打包整条 launch 工具链』的模式,你做工具站时可借鉴;二是它真实在投的词(keyword opportunity / aso audit / conversion funnel)显示 ASO 这块工具仍有人在做、仍有缝。归品类参考。
值得知道

→ 跟你 deroomai/tryonfy 在『AI 图像编辑』上邻接,属竞品/品类监控、不是新机会。值得看的是它的交互——把『手势 + prompt』组合成编辑动作,比纯文字 prompt 更可控,这点跟今天 HN Ideogram 那条『结构化输入比自然语言稳』呼应,你调生图编辑交互时可参考。做不了它的 B2B 品牌内容盘子,但交互思路可借。
值得知道
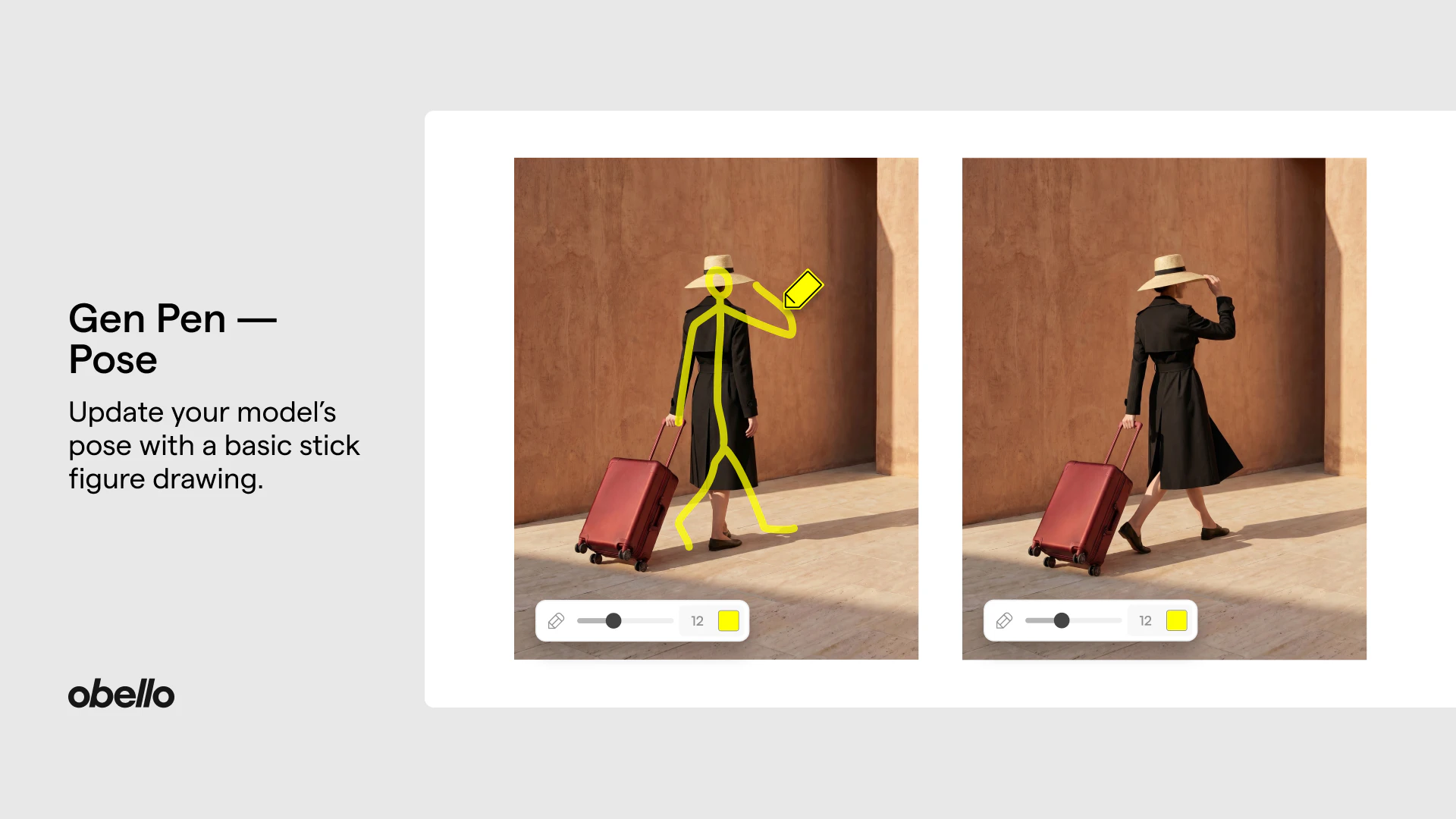
AI Image Combiner:把两张图合成一张的单点工具↗
→ 这是你最熟的那种『单一关键词 × 免费工具 × 程序化 SEO』打法,正好是你能做的。它把一个具体动作(合两张图)做成一个站、用 image combiner / merge two photos 这类词吃自然流量。对你:一是可借这个极简形态——别做大而全的图像编辑器,一个动作一个站、一组词;二是这词的竞争度别信感觉,拿 Semrush 验一下 merge photos / combine images online 的量和 KD 再决定值不值得碰。你做 deroomai/tryonfy 已有生图能力,复用做这种单点工具的边际成本低。
值得知道
AI Image Combiner:把两张图合成一张的单点工具↗

Easy MCP AI:把整套 WordPress 内容运营交给 AI 的 MCP↗
→ 你的站是 Next.js/CF 不是 WordPress,所以不是直接拿来用,但这条是个很值的方向信号——『用 MCP 把 SEO 内容运营全自动化』正在成型,而且它把 Semrush/DataForSEO 这类 SEO 数据源直接做进了 MCP。对你两点:一是它内置 SEO 数据源的做法值得抄到你自己的 MCP/脚本里(你本来就在用 Semrush 镜像查词);二是『从 idea 到发布不碰后台』这套内容流水线,跟你 daily-web 全自动、跟你程序化铺页的方向一致,可以拆它的工具清单看哪些能搬到你的栈。
值得知道
Easy MCP AI:把整套 WordPress 内容运营交给 AI 的 MCP↗

InfographicAI:一句话生成信息图的 AI 工具↗
→ 又一个『单一关键词 × AI 图像生成 × 程序化 SEO』的样本,跟 AI Image Combiner 一个套路、也是你能做的。它的真实关键词(infographic generator ai / ai infographic maker / auto generate infographics)就是现成的词矿提示——这类『把一句话变成某种图』的工具最容易用程序化页吃长尾。对你:可以把它和 AI Image Combiner 放一起,作为『单点图像工具 + 程序化 SEO』的选品池,挑一两个拿 Semrush 验词后做。注意它已在 TAAFT 有热度,说明品类有人在抢,得靠更细的长尾词或更好的免费额度切入。
值得知道
InfographicAI:一句话生成信息图的 AI 工具↗

supermemory:给 AI 应用挂的『记忆引擎』↗
600 stars/d→ 趋势提示,暂不用动。『给 AI 应用挂外部记忆』今天在 HN(Mnemo)和 GitHub(supermemory)同时冒头,值得记。如果你以后做带对话/个性化的工具(deroomai 记住用户偏好、daily-web 记画像做自我进化),这类 Memory API 能省你自己造轮子。现在你的『记忆』就是 MEMORY.md 这类文本文件够用,先 watchlist,等真要做个性化时再看这类方案成熟没。
扫一眼
supermemory:给 AI 应用挂的『记忆引擎』↗
600 stars/d→ 不沾你方向、做不了(家政垂直、本地服务),但作为样本值得记一眼:它把『某个垂直行业的获客全流程』打包成一个 AI stack。这跟你今天 Reddit 那条 GEO、跟 findloc.ai 的垂直 GEO 是一个大方向——选一个本地服务垂直、用 AI 把获客链条打通。你不会进家政,但这个『垂直 + 打包』的打法可以记进选品脑子里。
扫一眼
2026-06-02
10 条信号→ 契合度高——AEO/GEO 是你 SEO 主业的新前沿。它真实在投的不只 GEO,还叠了「本地选址情报」(site selection / foot traffic) 那层,那半边你不做;但「让 AI 引用你」的打法(schema + FAQ + 结构化数据)你能直接搬到三个站,几天能铺。
值得深看
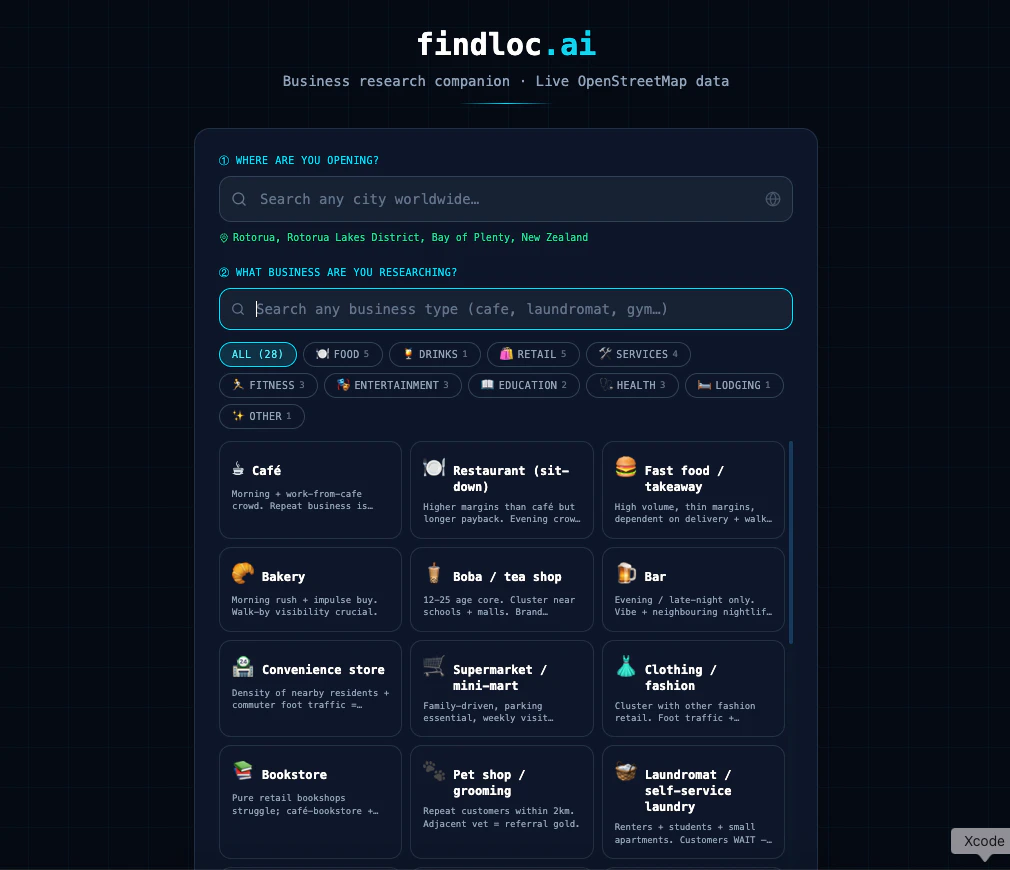
headroom:喂 LLM 之前先压掉 60-95% 的 token↗
1.3k stars/d→ 这条能直接用上。你本来就在用 RTK 压 CLI 输出省 token,headroom 是同一思路的另一块拼图——专门压「喂给模型的那一坨」:长日志、抓回来的网页、RAG 上下文。对 daily-web 这种每天要把大量 snapshot 和评论喂进来打分的流程,token 成本是隐形大头,挂个 MCP server 或代理在中间就能砍掉一截。值得拿你最重的那条链路(比如 Reddit 评论批量喂进来筛选)试一次,看实际省多少再决定要不要常驻。
值得知道
headroom:喂 LLM 之前先压掉 60-95% 的 token↗
1.3k stars/dVoxCPM2:无 tokenizer 的多语种 TTS,带语音克隆↗
783 stars/d→ 对你内容这块是个可落地的工具升级。公众号、产品 demo、短视频的旁白配音,过去要么用 ElevenLabs 那种按量付费、要么开源音色生硬;一个能本地跑的多语种开源 TTS 一旦质量够,就把「批量给内容配音」的成本压到接近零,还顺带解决出海多语言旁白。先存着,等你真要给 deroomai 或 tryonfy 做视频引流、或给公众号文章加语音版时,拿它和 ElevenLabs 比一轮音质再定。
值得知道
VoxCPM2:无 tokenizer 的多语种 TTS,带语音克隆↗
783 stars/dCloakBrowser:号称过掉所有反爬检测的 Playwright 平替↗
10 stars/d→ 这条你看了大概会会心一笑。你抓 Reddit 得挂 7897 代理、登 Google 得加 --disable-blink-features=AutomationControlled、天天跟反自动化检测斗,而 CloakBrowser 的承诺就是把这些指纹对抗在浏览器层一次性解决。它确实很新(总星还是 0),「30 项全过」是自卖自夸得打个折,但值得 fork 下来对你最头疼的那个站实测一次——尤其是 X 源现在还靠借登录态手抓,如果它真能 drop-in 替掉 Playwright,daily-web 的抓取稳定性和 X 自动化能省不少事。
值得知道
CloakBrowser:号称过掉所有反爬检测的 Playwright 平替↗
10 stars/dAIClothSwap:tryonfy 的正面竞品又多一个↗
→ 竞品监控档(非新蓝海)——它是 tryonfy 的直接同类、你已经在做,所以不是「我能做的新机会」而是竞品情报:拿它的真实词(ai clothes swap / virtual try-on…)对一遍 tryonfy 的词覆盖、看缺哪些,顺带盯它的出图速度和定价。
值得知道
AIClothSwap:tryonfy 的正面竞品又多一个↗

BlogSEO:在 Google 和 ChatGPT 上自动驾驶排第一↗
→ 契合度高——SEO 自动化正是你主业。真实打法(AI 日更文章 + 自动发布 + 外链交换 + 主打 Google·ChatGPT 双排名)你能部分复刻;不必买它,抄动作即可。
值得知道
BlogSEO:在 Google 和 ChatGPT 上自动驾驶排第一↗
Oginify:AI 一键生成 Open Graph 图↗
→ 契合度中——OG 图生成是低门槛小工具、你能做。真实词「open graph image generator」需求稳、竞争看着不挤,值得丢工具验证一下,够蓝海就铺个引流小站。
值得知道
Oginify:AI 一键生成 Open Graph 图↗

→ 契合度低——你不做视频工具,这方向不碰。价值只在情报:它的真实词(video intelligence / ai rough cut)说明「理解素材再剪」成了新品类,将来做视频引流时它是分发工具备选,不是你能下场的赛道。
扫一眼

→ 契合度中——浏览器视频实时翻译,门槛中等、技术上你能做,但跟三个站定位不搭、不建议碰。真实词(live video translation / ai subtitles any video)可丢进待验证词单,看出海与语言学习受众有没有量。
扫一眼
Pixelle-Video:又一个 AI 全自动短视频引擎↗
9 stars/d→ 单看产品没什么新意,但连着两天有新的开源短视频引擎上榜,说明「AI 批量产短视频」这条线还在快速堆人。对你的含义跟昨天一样:拿来给 deroomai、tryonfy 批量做 Reels 或 Shorts 引流是条低成本路子,但同时意味着这赛道的 slop 只会更多。真要做,差异点还得落在真实 demo、真人讲解上——纯模板拼接的视频平台已经看腻了。这种工具看一眼知道它存在即可,不用急着上。
扫一眼
Pixelle-Video:又一个 AI 全自动短视频引擎↗
9 stars/d2026-06-01
13 条信号AI Skill 生态集体爆发:设计、PPT、学术、抓图全在做 agent skill↗
485 stars/d→ 这条对你是选题和工具双重信号。趋势层面:『skill』正在变成像当年 npm 包一样的东西——把一套领域知识 + 流程打包给 agent 复用,连 GreenSock 这种老牌库都出官方 skill 了。对你的直接用法有两条:一是工具,impeccable 你已经在用,gsap-skills、ppt-skill 这些可以直接拿来给自己提效(比如公众号配图、落地页动效);二是选题,如果哪天想做开发者向的内容或工具,『某领域的 AI skill』是个正在起量、还不拥挤的方向。值得把这批 repo 收藏起来当工作流弹药库。
值得深看
AI Skill 生态集体爆发:设计、PPT、学术、抓图全在做 agent skill↗
485 stars/dImaginPrompt:任意图片秒反推 AI 提示词↗
→ 契合度中高——image-to-prompt 沾你的图像栈(deroomai/tryonfy)。它的真实词海量(reverse prompt / image describer / 各家模型 prompt),说明这是个有量、可程序化铺页的词矿,你能做个轻工具引流。值得丢工具验证量级。
值得深看
ImaginPrompt:任意图片秒反推 AI 提示词↗

MoneyPrinterTurbo:一键用 AI 生成高清短视频↗
3.4k stars/d→ 对你有两层。一是分发工具:如果想给 deroomai/tryonfy 做短视频引流(TikTok/Reels/YouTube Shorts),这类一键生成是低成本起量的路子,能把产品 demo 或攻略批量转成视频。二是个警示信号:AI 批量产视频的门槛已经低到这种程度,意味着短视频赛道的 slop 会和图文一样泛滥——你要做就得想清楚差异点在哪(真实数据、真人视角),否则就是给平台加噪音。结合今天 Reddit 的认知负债那条看,『批量生成』和『稀缺的真东西』之间的剪刀差,正是内容站的机会所在。
值得知道
MoneyPrinterTurbo:一键用 AI 生成高清短视频↗
3.4k stars/dmarkitdown:把各种文件和 Office 文档转成 Markdown↗
3k stars/d→ 实用工具一枚,值得收进工具箱。任何你要把现成资料(竞品文档、PDF 报告、Office 文件)喂给 Claude 处理的场景,markitdown 能省掉手动整理的功夫,输出干净的 Markdown 直接进 prompt。配合今天另一个上榜的 headroom(喂 LLM 前压缩 token 60-95%),这俩拼起来就是一条『文件 → 干净 Markdown → 压缩 → 喂模型』的低成本预处理流水线,对你做任何批量 AI 处理(选题、内容生成、数据清洗)都能直接用。
值得知道
markitdown:把各种文件和 Office 文档转成 Markdown↗
3k stars/dScrapling:自适应反爬的 Web 抓取框架↗
1.5k stars/d→ 这条对你 daily-web 的抓取环节是现成弹药。你现在 HN/Reddit 要挂代理、TAAFT 要 curl_cffi 绕 Cloudflare、各源各写一套——Scrapling 这类自适应框架的卖点正是统一处理这些反爬细节。不一定马上迁,但值得评估它能不能替掉你 scripts/ 里那堆零散的抓取 + 代理逻辑,把维护成本降下来。抓取稳定性是 daily-web 全自动化的命门,这块的工具升级直接关系到你能不能真做到『无人值守跑日报』。
值得知道
Scrapling:自适应反爬的 Web 抓取框架↗
1.5k stars/dAI Memory 成显学:supermemory、agentmemory、EverOS 一起上榜↗
647 stars/d→ 这条目前还 early、不急着用,但跟你的 daily-web 重构方向高度相关。你定的『自我进化』就是要靠记忆记住用户画像和每次反馈、越跑越契合——现在这条用的是 Claude Code 的 memory 文件,而这批开源 memory 引擎正是把这件事做成基建的尝试。值得跟一阵子:等它们成熟,可能比手搓 memory 文件更适合做 daily-web 的『记画像 + 漂移』那层。先收藏,到要动自我进化机制时回头看。
值得知道
AI Memory 成显学:supermemory、agentmemory、EverOS 一起上榜↗
647 stars/dTAAFT 一天上俩 SEO / AI 搜索增长工具:TrafficLift、Uplift AI↗
→ 契合度高——AI SEO 审计正挨着你主业。它真实打法(24h 出 SEO 修复清单 + 同时排 Google 和 AI agent)值得当 checklist 参考;但你自己有 GSC、Semrush,不一定要买。当竞品和方法论看。
值得知道
TAAFT 一天上俩 SEO / AI 搜索增长工具:TrafficLift、Uplift AI↗

→ 契合度低——B2B BI 工具,你不做。价值只在情报:MCP 正成为产品的新入口(把数据/能力塞进 AI 对话),等你的攻略或情报数据想被 AI 调用时是个形态参考,但这产品本身你不碰。
扫一眼
→ 契合度低——Meta ads 拼团降本,你做 SEO 自然流量为主、不走付费投放这路。情报价值:「拼团压广告单价」是个真需求信号,但不是你的方向。
扫一眼

→ 契合度中(自用)——LLM 成本监控,跟你用 RTK 省 token 同向。当工具看:给批量 AI 流程挂一层省钱可评估;不是你要做的产品。
扫一眼

→ 契合度低——开发者基建库,你不做 dev tool,跳过。它的真实词(统一各家邮件 provider)说明「多 provider 抽象」是个开发者痛点,仅此而已。
扫一眼
SemanticGuard:削减 LLM API 成本,又不破坏输出↗
→ 契合度中(自用)——LLM 语义缓存降本,跟 Tokenwise 一类。批量调模型省钱可评估,不是产品方向。
扫一眼
SemanticGuard:削减 LLM API 成本,又不破坏输出↗
ReplyForMe:AI 自动回复 Google 评论↗
→ 契合度低——Google 评论自动回复,本地商家工具,你不做,跳过。
扫一眼
ReplyForMe:AI 自动回复 Google 评论↗
